0%
Theme NexT works best with JavaScript enabled
模块结构
sharding-core-parse-common,实现了SQL解析的主要功能。
sharding-core-parse-mysql,sharding-core-parse-oracle,sharding-core-parse-postgresql,sharding-core-parse-sqlserver。这四个模块分别对应四个不同的数据库类型,里面包含该类型数据库特有的一些实现类。
sharding-core-parse-spi,主要定义了两个接口。SQLParser,抽象了antlr4生成的语法解析器的解析方法execute()。SQLParserEntry,抽象了获取antlr4生成的词法解析器和语法解析器的方法。
sharding-core-parse-test,主要包含了对sharding-core-parse模块内部主要功能的测试,使用jaxb技术来定义测试用例和测试结果。
模块结构图
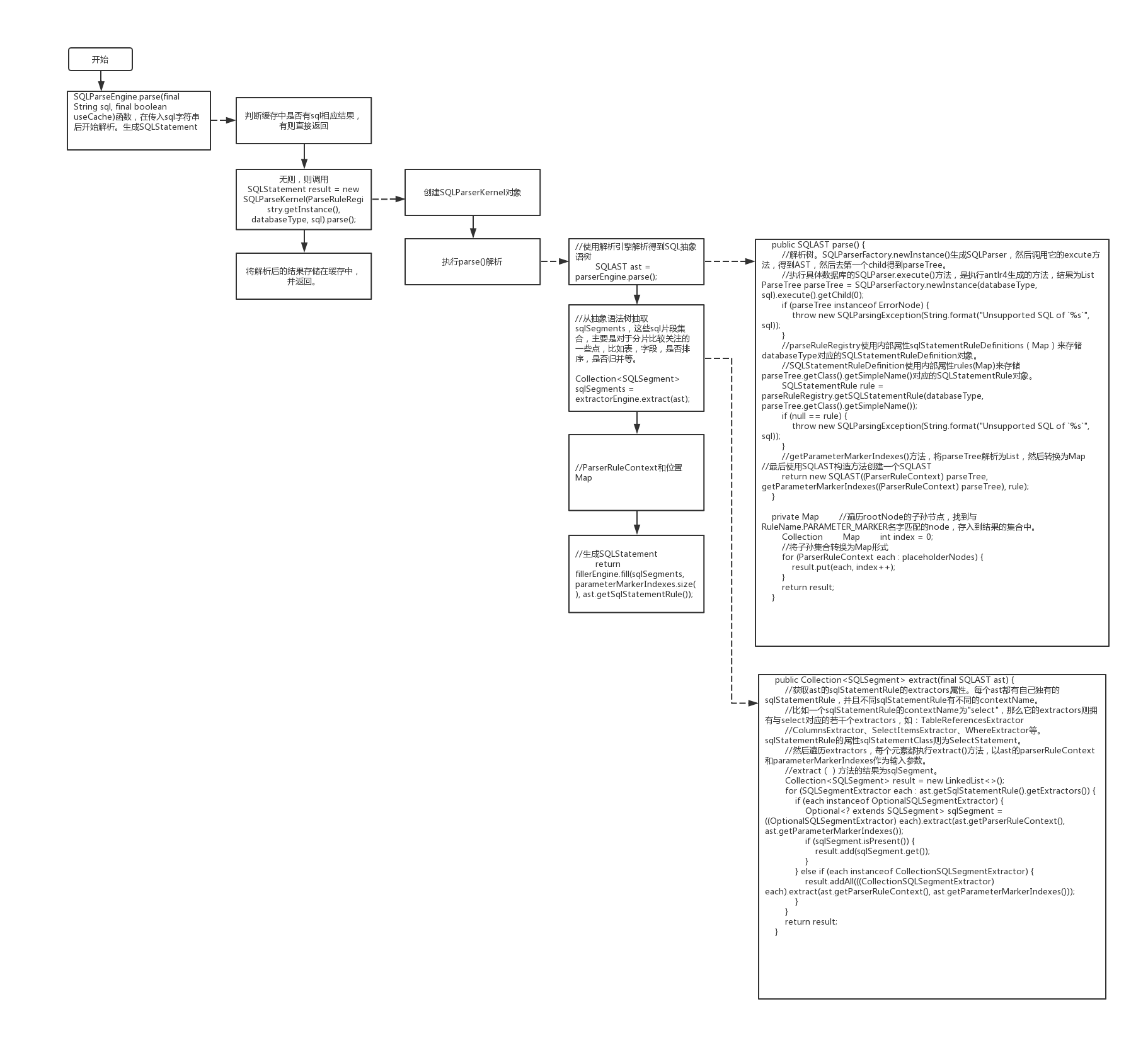
主要逻辑流程和关键类分析
设计模式和设计原则
享元模式getSQLParseEngine()方法显示了享元模式的主要逻辑,首先判断ENGINES(Map类型)里面是否含有databaseType.getName()相应的元素,如果有则直接返回,否则根据databaseType来创建SQLParseEngine对象,缓存在ENGINES中,并返回此对象。1 2 3 4 5 6 7 8 9 10 11 12 13 public static SQLParseEngine getSQLParseEngine(final DatabaseType databaseType) { if (ENGINES.containsKey(databaseType.getName())) { return ENGINES.get(databaseType.getName()); } synchronized (ENGINES) { if (ENGINES.containsKey(databaseType.getName())) { return ENGINES.get(databaseType.getName()); } SQLParseEngine result = new SQLParseEngine(databaseType); ENGINES.put(databaseType.getName(), result); return result; } }
依赖倒转原则org.apache.shardingsphere.core.parse.core.filler,org.apache.shardingsphere.core.parse.core.extractor,org.apache.shardingsphere.core.parse.sql.segment,org.apache.shardingsphere.core.parse.sql.statement等。这些包的内部结构体现了这一原则。比如SQLStatementFillerEngine类的fill()方法内部调用SQLSegmentFiller接口,SQLSegmentFiller接口的实现类定义在impl包中。sharding-core-parse-common定义了SQLSegmentExtractor和SQLSegmentFiller接口,sharding-core-parse-spi定义了SQLParser接口和SQLParserEntry接口。,sharding-core-parse-mysql,sharding-core-parse-oracle,sharding-core-parse-postgresql,sharding-core-parse-sqlserver这四个模块会不同程度地实现上面的接口,不同的数据库都有各自特点,需要实现自身独有的实现类。依赖倒转为此提供了便捷,使得不同数据库只关注自身的实现。
工厂模式newInstance()体现了简单工厂的设计思想。它将对象的创建和使用分离开,对使用者屏蔽了复杂的创建过程。相关代码和注释如下:1 2 3 4 5 6 7 8 9 10 11 12 public static SQLParser newInstance(final DatabaseType databaseType, final String sql) { //NewInstanceServiceLoader.newServiceInstances()返回一个装满SQLParserEntry类型对象的List //for循环遍历这个List for (SQLParserEntry each : NewInstanceServiceLoader.newServiceInstances(SQLParserEntry.class)) { //DatabaseTypes.getActualDatabaseType()根据名字返回对应databaseType,如果each的databaseType能够与传入的参数databaseType匹配则进行下面的计算 if (DatabaseTypes.getActualDatabaseType(each.getDatabaseType()) == databaseType) { //创建SQLParser对象 return createSQLParser(sql, each); } } throw new UnsupportedOperationException(String.format("Cannot support database type '%s'", databaseType)); }