Antlr相关
实例入门
在安装完 antlr 之后,可以编写简单的 g4 文件
1 | grammar Hello; |
运行如下命令
antlr4 Hello.g4javac *.javaalias grun=‘java org.antlr.v4.runtime.misc.TestRig’TestRig 是一个调试工具,使用 alias 给它起了一个别名。直接执行grun可以得到帮助信息。grun Hello r -tokenshello parrtEOF
得到如下结果
1 | [@0,0:4='hello',<'hello'>,1:0] |
解析结果:比如 parrt。@1 表明该词法符号在第 2 个位置,parrt 位于第 6 个到第 10 个位置之间,词法符号类型是 ID,位于输入文本的第 1 行,第 6 个位置处。
调试工具
TestRig 是一个调试工具。alias grun=‘java org.antlr.v4.runtime.misc.TestRig’ TestRig 是一个调试工具,使用 alias 给它起了一个别名。直接执行grun可以得到帮助信息。
- 对于
Hello语法,执行grun Hello r -tokens可以得到解析的各个 token 的信息。 - 对于
Hello语法,执行grun Hello r -tree可以得到解析的树信息。 - 对于
Hello语法,执行grun Hello r -gui可以得到解析的树的图形信息。
通过执行 grun,可以查看可以使用的选项。
1 | $ grun |
-ps files.ps 以 PostScript 格式生成可视化语法分析树,然后将其存储于 file.ps。本章中的语法分析树的图片就是使用-ps 选项生成的。
-encoding encodingname 若当前的区域设定无法正确读取输入,使用这个选项指定测试组件输入文件的编码。例如,在 12.4 节中我们需要通过这个选项来解析日语 XML 文件。
-trace 打印规则的名字以及进入和离开该规则时的词法符号。
- diagnostics 开启解析过程中的调试信息输出。通常仅在一些罕见情况下使用它产生信息,例如输入的文本有歧义。
- SLL 使用另外一种更快但是功能稍弱的解析策略。
ANTLR4 的 IntelliJ 插件
打开 g4 文件,选择特定的规则名字,然后右键选择 Test Rule ****。
会在底部弹出框,左侧显示输入的 sql 语句,右侧显示分析的后 tree 以及 Hierarchy,Profiler。
语法分析器
Antlr 依据我们定义的语法规则,产生一个递归下降的语法分析器。下降过程就是从语法分析树的根节点开始,朝着叶节点进行解析的过程。递归下降的语法分析其实际是若干方法的结合,每个方法对应一条规则。递归下降属于自上而下的语法分析器的一种实现。
首先调用的规则,即语义符号的起始点,就会成为语法分析树的根节点。比如:调用上面的 r()方法,作为起始点。
语法分析数的构造过程:识别匹配的规则,将对应规则的方法映射到语法分析树中。
一般规则分为:单一分支,多分支。例如:多个规则 assign,ifstat
单一分支,如:stat: assign;
多分支,如:stat: assign|ifstat;
顺序解析
单一分支,只需要顺序匹配词汇符号。
多分支解析
多分支,需要检查下一个词法符号或者多个词法符号,来决定选择哪个备选分支。这个过程成为预测或语法分析决策。
如果在预测过程中,发现多个分支都匹配的话,则出现了规则的定义出现了歧义,需要解决。
歧义
例如下面这个语法就存在歧义
1 | stat: expr ';' |
一般情况下要确保语法分析器能够选择唯一匹配的备选分支。不过当存在多个备选分支时,ANTLR 会选取备选分支中的第一条。比如本例中就会选择expr ';'
如下存在词法歧义,begin 是一个关键字,同时也是一个标识符。
词法分析器会匹配最长字符串,如果输入文本 beginner 只会匹配上例中的 ID 这条词法规则。ANTLR 词法分析器不会把它匹配为关键字 BEGIN 后跟着标识符 ner
1 | BEGIN : 'begin' ; |
语法分析树
构建应用逻辑和语法松耦合的语言类应用程序的关键在于,令语法分析器建立一颗语法分析树,然后在遍历该树的过程中触发应用逻辑代码。
语法分析树的建造过程:词法分析器处理字符序列并将生成的词法符号提供给语法分析器,语法分析器随即根据这些细信息来检查语法的正确性并建造出一颗语法分析树。
1 | CharStream->(Lexer)->TokenStream->(Parser)->ParseTree(RuleNode子类+TerminalNode) |
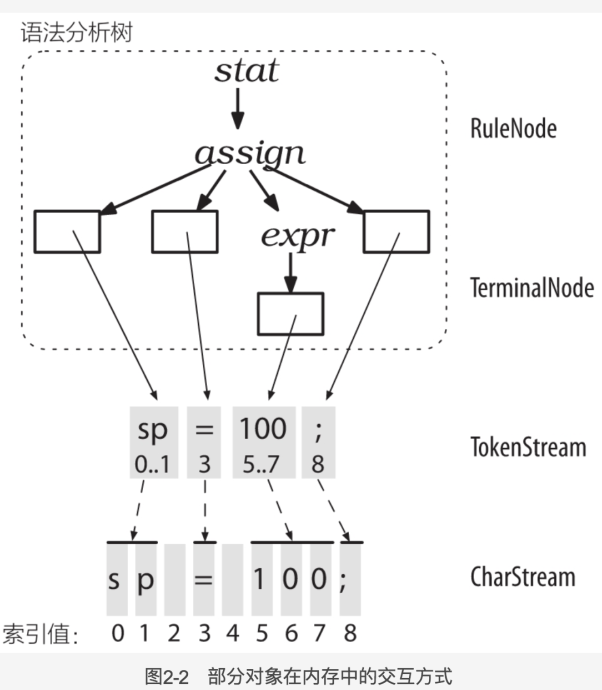
ANTLR 使用共享数据结构节约内存,具体办法是:语法分析树中的叶子节点仅仅是盛放词法符号流中的词法符号的容器。每个词法符号都记录了自己在字符序列中的开始位置和结束位置,而非保存子字符串的拷贝。
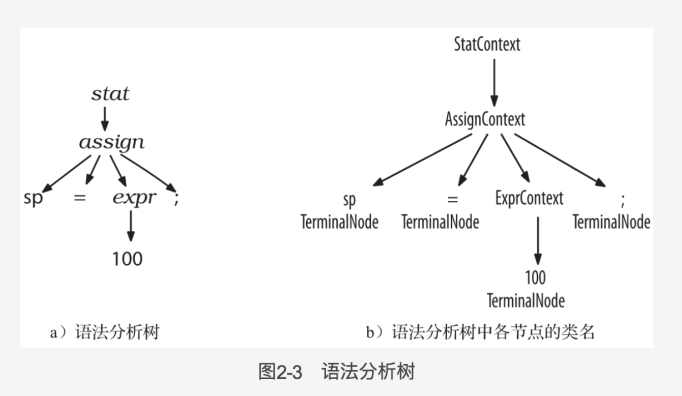
ParseTree 有两个子类:RuleNode 的子类(非叶子) 和 TerminalNode(叶子)。 RuleNode 的子类包括:StatContext 和 ExprContext.Context 对象知道自己识别的词组中,开始和结束位置处的词法符号,同时提供访问该词组全部元素的方法比如 statContext 类有 ID()和 expr()方法。有了这些方法,我们就可以遍历并操作树中节点。实际上遍历树的机制都是由 ANTLR 生成的代码
语法分析树的访问-监听器、访问器
为了构建一个语言类应用程序,语法分析器需要在遇到特定的输入语句、词组或者词法符号时触发特定的行为。这样的词组->行为的集合构成了我们的语言类应用程序,或者,至少担任了语法和外围程序间接口的角色。
监听器和访问器的区别在于,监听器方法不负责显示调用子节点的访问方法(visit())。访问器必须显式触发对子节点的访问,树的遍历过程才能正常进行,所以访问器可以控制访问的顺序以及节点被访问的次数。
监听器
ANTLR 提供了 ParseTree-Walker 类,自动遍历树然后生成事件并调用监听器。
每个语法文件都会生成一个 ParseTreeLisener 的子类,里面每个规则都有对应的 enter 方法和 exit 方法(),这些方法也称为”事件方法”。这些方法的入参是 ×××Context,提供该方法所需要的所有信息。监听器的操作逻辑在这些 enter 和 exit 方法内添加。下图显示了 ParseTreeWalker 对监听器方法的完整的调用顺序。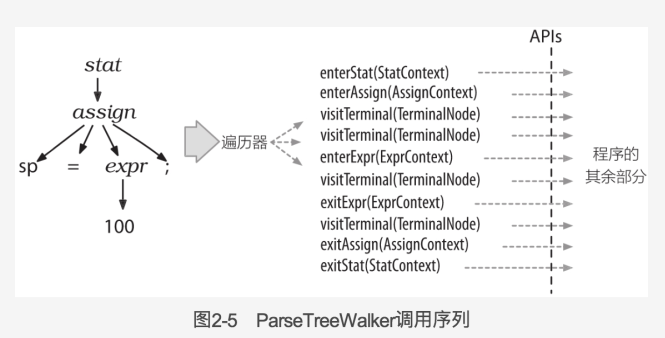
访问器
有时候我们希望手动控制遍历数的过程,通过显示的方法调用来访问子节点。在命令行中加入-visitor 选项可以指示 ANTLR 为一个语法生成访问器接口,语法中的每条规则对应接口中的一个 visit 方法。ANTRL 提供了访问器接口和一个默认实现类,这样我们自己只需要覆盖接口中我们感兴趣的方法。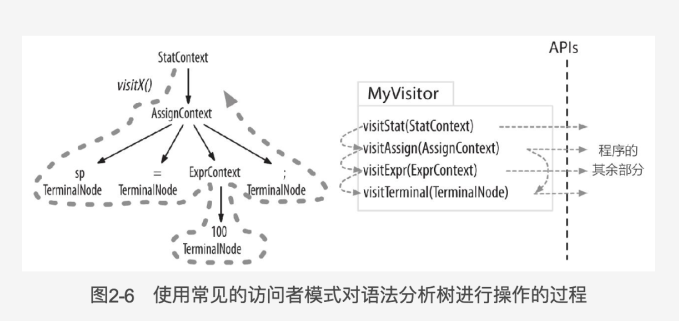
调用方式如下:
1 | ParseTree tree = ...;//语法分析数 |
在事件方法中共享信息
使用访问器遍历语法分析树,使用访问器方法来返回值。优缺点:无法传递参数,访问器方法只能返回值。
使用类成员在事件方法之间共享数据,使用栈来模拟返回值。在上下文类中维护一个栈字段,以与 java 调用栈相同的方式,模拟参数和返回值的入和出栈。优缺点:手工操作栈存在失误的可能性,不过栈比较节省空间,所有局部结果的存储在树遍历完成后都会被释放。
通过对语法分析树的节点进行标注来存储相关数据,通过规则参数和返回值为节点添加字段。在上下文中维护一个 Map 字段,用对应的值来标注节点。优缺点:树标注是我个人的首选解决方案,因为它允许我向事件方法提供任意信息来操纵语法分析树中的各个节点。通过该方案,我可以传递多个任意类型的参数值。在很多情况下,标注比存储转瞬即逝的值的栈更好。使用它,在众多方法中来回传递数据也更不容易事务。这种方案的唯一缺点是,在整个遍历过程中,局部结果都会被保留,因此具有更大的内存消耗。另一方面,某些程序恰好需要标注语法分析树的方案,例如 8.4 节。该程序需要对语法分析树进行多次遍历,将第一趟遍历得到的数据完整地存储在树中是合理的,这样,第二趟遍历就能非常容易地获取这些数据。总之,对数进行标注的方案异常灵活,同时内存占用也处于可接受的范围。
- 为规则添加返回值
1
2
3
4
5e returns [int value]
: e '*' e # Mult
| e '+' e # Add
| INT # Int
;ANTLR 会将所有的参数和返回值放入相关的上下文对象中,这样,value 就成为 EContext 的一个字段。
1
2
3
4public static class AddContext extends ParserRuleContext {
public int value;
...
}在对监听器方法进行实现的时候,就可以按照如下方式存储值
1
2
3
4public void exitAdd(LExprParser.AddContext ctx) {
// e(0).value 是备选分支中的第一个e子表达式的值
ctx.value = ctx.e(0).value + ctx.e(1).value; // e '+' e #Add
}- 使用 ParseTreeProperty 类来存储各个节点及对应的值
定义
1
2
3
4
5
6
7
8
9
10
11public static class EvaluatorWithProps extends LExprBaseListener {
/** 使用Map<ParseTree,Inteer>将节点映射到对应的整数值 **/
ParseTreeProperty<Integer> values = new ParseTreeProperty<Integer>();
public void setValue(ParseTree node, int value) { values.put(node,value);}
public int getValue(ParseTree node) {return values.get(node);}
public void exitAdd(LExprParser.AddContext ctx) {
int left = getValue(ctx.e(0));
int right = getValue(ctx.e(1));
setValue(ctx, left+right);
}
}调用
1
2
3
4ParseTreeWalker walker = new ParseTreeWalker();
EvaluatorWithProps evalProp = new EvaluatorWithProps();
walker.walk(evalProp, tree);
System.out.println("properties result = "+ evalProp.getValue(tree));总结。为获取可复用的语法,我们需要使其与用户自定义的动作分离。这意味着将所有程序自身的逻辑代码放到语法之外的某种监听器或者访问器中。监听器和访问器通过操纵语法分析树来完成工作,ANTLR 会自动生成合适的接口和默认实现类,以便对语法分析树进行遍历。但是,由于事件方法的签名是固定的,无法由程序自行决定,我们找到了三种在事件方法中共享数据的方案。
语法规则
例子 1
文件 ArrayInit.g4
1 | /** 语法文件通常以grammar关键字开头 |
ANTLR 对 g4 文件解析后,会生成如下文件:ArrayInitParser.java, ArrayInitLexer.java,ArrayInit.tokens,ArrayInitLexer.tokens,ArrayInitListener.java:ArrayBaseListener.java.
1 ArrayInitParser.java:对应语法 ArrayInit,每条规则对应里面一个方法。
2 ArrayInitLexer.java:用于识别词法规则和文法规则。它是通过 ANTLR 分析词法规则 INT 和 WS,以及语法中的字面值‘{’ ‘}‘ ‘,’生成的。
3 ArrrayInit.tokens: ANTLR 会给每个我们定义的词法符号指定一个数字形式的类型,然后将他们的对应关系存储于该文件中。
4 ArrayInitListener.java 和 ArrayBaseListener.java: 在遍历 AST 时,遍历器能够触发一系列事件,并通知我们提供的监听器对象。ArrayInitListener 接口给出了这些回调方法的定义,ArrayBaseListener 是该接口的默认实现类,为其中的每个方法提供了一个空实现。
ANTLR 语法基本标记
- 语法包含一系列描述语言结构的规则。这些规则既包括类似 stat 和 expr 的描述语法结构的规则,也包括描述标识符和整数之类的词汇符号的规则
- 语法分析器的规则以小写字母开头
- 词法分析器的规则以大写字母开头
语法规则
- 我们使用|来分隔同一个语言规则的若干备选分支,使用圆括号把一些符号组合成自规则。例如,子规则(‘*‘|’/‘)匹配一个乘法符号或者触发符号。
- 使用?表达一个或 0 个,使用*表达多个或 0 个,使用+表达至少 1 个。
- 词法符号依赖,比如(),[],{}等。成对出现的符号。符号使用’’包裹起来。
- 处理嵌套模式可以使用递归规则处理,规则的定义中包含对自身的调用。有规则直接引用自身称为直接递归,规则间接引用自身称为间接递归。
- 处理优先级,左结合。ANTLR 在解析输入的语句的时候采用左结合的特性,当处理“1+2*3”的时候,就会先处理加法。这样是有问题的,解决这个问题的办法是在定义语法的时候,乘法的语法写在加法前面,这样,ANTLR 会优先匹配乘法,然后再匹配除法。
- #标签可以标注备选分支,为每个备选分支单独生成一个监听器方法。如果没有#进行标注,则之后语法规则名对应的一个监听器方法。
1 | expr: <assign=right> expr '^' expr #Index |
但是,向指数运算这种右结合的情况,就需要使用<assign=right>单独指定。
左递归
- 左递归规则含义:在某个备选分支的最左侧位置,直接或间接调用了自身。例如:
1 | expr: INT|ID|'('expr')' |
- 带有优先级的左递归。在面对 1+23 这样的输入是,根据优先级原则,会按照 1+(23)来处理。
1 | expr: expr '*' expr |
- ANTLR 通过下列四种子表达式运算模式来认定一条规则为左递归规则。
- 二元。
1
2
3
4expr: ...
| expr ('<' | '>' | '= ') expr
...
; - 三元
1
2
3
4expr: ...
| expr '?' expr ':' expr
...
; - 一元前缀
1
2
3
4
5
6expr:...
|'(' type ')' expr
...
|('+'|'-'|'++'|'--') expr
...
; - 一元后缀
1
2
3
4
5
6expr:...
|expr ‘.’ Identifier
...
|expr '.' 'super' '(' exprList? ')'
...
;
- 二元。
词法规则
匹配标识符
ID: [a-zA-Z]+;匹配数字
ID: [0-9]+;匹配字符串常量。
STINRG: '"' .*? '"'。点通配符匹配任意的单个字符。因此,*.就是一个循环,它匹配零个或多个字符组成的任意字符序列。显然,它可以一直匹配到文件结束,但这没有任何意义。为解决这个问题,ANTLR 通过标准正则表达式的标记‘?’,提供了对非贪婪匹配子规则的支持。非贪婪匹配的基本含义是:“获取一些字符,直到发现匹配后续子规则的字符为止”。更准确的描述是,在保证整个父规则完成匹配的前提下,非贪婪子规则匹配数量最少的字符。不过目前这个字符串不支持字符串内包含双引号。匹配注释并丢弃。
COMMENT:'/*' ,*? '*/' -> skip;. skip 是丢弃的含义。匹配空白字符并丢弃。
WS:[\t\n\r]+ -> skip
ANTLR 解析过程的异常处理
ANTLR 语法分析器能够自动报告语法错误并从错误中恢复继续工作。比如前一个错误的表达式,则输出错误信息。然后继续正确地解析第二个表达式。
ANTLR 的错误处理机制有很高的灵活性。我们可以修改输出的错误信息,捕获识别过程中的异常,甚至改变基本的异常处理策略。
在语法和词法文件中添加动作
定制语法分析
- 在语法中嵌入任意动作
我们创建一个构造器,这样我们就能传入希望提取的列号;另外,我们需要在 row 规则的”(…)+”循环中放置一些动作。
下面的例子,是将输入文本中的指定列显示出来。
详细的内容,会在第 10 章。
1 |
|
- 使用语义判定改变语法分析过程(第 11 章)
下面的语法用来处理一组整数”2 9 10 3 1 2 3”。第一个数字 2 代表接下来匹配两个数组 9 和 10。紧接着数字 3 告诉我们匹配接下来的三个数字。
我们的目标是创建一份名为 Data 的语法,将 9 和 10 分为一组,然后 1,2,3 分为一组。
Data 语法的关键在于一段动作,它的值是布尔类型的,称为一个语义判定:{$i<=$n>}?。它的值在匹配到 n 个输入整数之前保持为 true,其中 n 是 sequence
语法中的参数。当语义判定的值为 false 时,对应的备选分支就从语法中“消失”了,因此,它也就从生成的语法分析器中“消失”了。在本例中,语义判定的值为 false 使得”(…)*“循环终止,从 sequence 规则返回。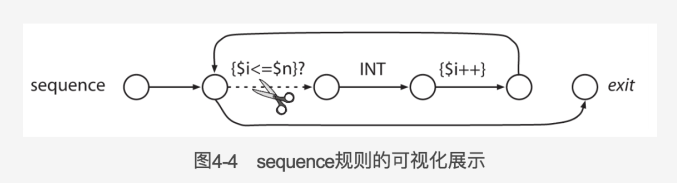
1 |
|
定制词法分析
- 孤岛语法:处理相同文件中的不同格式
mode INSIDE 定义模式,INSIDE 模式用于识别 XML 标签,默认模式用于识别标签之外的文本。
->定义了动作进入到 INSIDE 模式下
->定义了动作 popMode,从 INSIDE 模式下退出。
1 |
|
重写输入流
TokenStreamRewriter 对象可以改写输入的 TokenStream。关键之处,TokenStreamRewriter 对象实际上修改的是词法符号流的“视图”而非词法符号流本身。它认为所有对修改方法的调用都只是一个“指令”,然后将这些修改放入一个队列;在未来词法符号流被重新渲染为文本时,这些修改才会被执行。在每次我们调用 getText()的时候,rewriter 对象都会执行上述队列中的指令。这样的方法在源代码插桩或者重构等场合下非常有效。
1 |
|
- 将词法符号送入不同通道
忽略却保留注释和空白字符的秘诀是将这些词法符号送入一个“隐藏通道”。语法分析器只处理一个通道,因此我们可以将希望保留的词法符号送入其他通道内。
1 |
|
将生成的语法分析器与 Java 程序集成,并使用监听器遍历处理
例子 1
Test.java
此例子的目标是将 Java 中,类似{99, 3, 451}的 short 数组翻译成”\u0063\u0003\u01c3”
1 |
|
ShortToUnicodeString.java
当遍历 AST 的时候,会对监听器里的方法进行回调。ArrayInitBaseListener 实现了 ArrayInitListener 接口的每个方法,我们只需要继承 ArrayInitBaseListener 并重写自己感兴趣的方法,就可以达到目的。ShortToUnicodeString 中的方法将翻译输入数据的一部分并将结果打印出来。
1 |
|
例子 2
LibExpr.g4
此例子用来展示,将语法词法规则分布到多个不同文件中。
使用 import 功能,可以将一个大的语法文件分隔成小的,然后 import 导入连到一起。
1 |
|
CommonLexerRules.g4
1 |
|
ExprJoyRide.java
1 |
|
例子 3 访问器
LabeledExpr.g4
为每个备选分支定义一个标签,标签以#开头。这样 ANTLR 会为每个备选分支生成不同的访问器方法。这样我们就可以对每种输入都获得一个不同的事件。
1 |
|
1 |
|
使用如下命令可以生成 visitorantlr4 -no-listener -visitor LabeledExpr.g4
可以生成,LabeledExprBaseVisitor.java,LabeledExprParse.java,LabeledExprLexer.java,LabeledExprVisitor.java。
LabeledExprVisitor 是接口,LabeledExprBaseVisitor 是默认实现类。我们可以继承 LabeledExprBaseVisitor 然后重写里面的函数来实现自定义的逻辑。
EvalVisitor 内重写的方法对应备选分支的标签。里面引用的 JAVA 常量如:MUL,DIV 等。也是在语法文件中定义的词法符号名字。
1 |
|
例子 4
使用监听器来对 java 语法进行分析,根据实现类可以生成对应的接口定义,并保留注释
Java.g4
1 |
|
ExtractInterfaceListener.java
1 |
|
ExtractInterfaceTool.java
将自定义的监听器集成到程序里,并遍历
1 |
|
错误报告与恢复
入门
ANTLR 在解析语法的时候,可以发现语法和词法的错误并给予提醒,尽管语法有错误,语法分析过程还是照常进行。除了产生良好的错误消息和利用剩余的输入进行重新同步之外,语法分析器还必须能够移动到何时的位置继续语法分析过程。
修改和转发 ANTLR 的错误消息
处理语法错误信息
默认情况下,ANTLR 将所有的错误消息送至标准错误(standard error),不过我们可以通过实现接口 ANTLRErrorListener 来改变这些消息的目标输出和内容。该接口有一个同时应用于词法分析器和语法分析器的 syntaxError()方法。syntaxError()方法接收各式各样的信息无论是错误的位置还是错误的内容。它还接收指向语法分析器的引用,因此我们能够通过引用来查询识别过程的状态。
1 | public static class VerboseListener extends BaseErrorListener { |
使用这种方法,我们的程序就能在语法分析器调用其实规则之前,轻易地为其增加一个错误监听器
1 | SimpleParser parser = new SimpleParser(tokens); |
在我们增加自定义的错误监听器之前,我们需要移除输出目标是控制台的内置错误监听器,以防出现重复的错误消息。
处理有歧义的语法信息
有时候用户输入的语法可以匹配到我们定义的多个语法分支,这是就存在歧义,默认情况下语法分析器不会通知用户,因为这不是用户的错。而是,我们定义的语法规则的问题。如果希望通知用于,则请使用 addErrorListener()方法添加一个 DiagnosticErrorListener 的实例来告知语法分析器。
1 | parser.removeErrorListeners();//移除ConsoleErrorListener |
此外,你还应当告诉语法分析器,你对所有的歧义告警都感兴趣,而不仅仅是哪些可以快速检测到的。出于效率方面的原因,ANTLR 的决策机制并不是总能发现所有的歧义信息。下面是令语法分析器报告所有歧义的方法:
1 | parser.getInterpreter().setPredictionMode(PredictionMode.LL_EXACT_AMBIG_DETECTION); |
在开发过程中使用上面提到的诊断错误监听器是个好主意,因为 ANTLR 工具不会对歧义性语法结构提出静态告警。在 ANTLR4 中,只有运行状态的语法分析器才能检测到歧义。这就像是 Java 中静态类型机制和 Python 中动态类型机制的差别。
自动错误恢复机制
错误恢复指的是允许语法分析器在发现语法错误后还能继续的机制。语法分析器在遇到无法匹配词法符号的错误时,执行单词法符号补全和单词法符号移除。如果这些方案不奏效,语法分析器将向后查找词法符号,直到它遇到一个符合当前规则的后续部分的合理词法符号为止,接着,语法分析器将会继续语法分析过程,仿佛什么事情都没有发生过一样。也就是,发生语法错误后从错误中恢复,然后继续语法解析。
- 通过扫描后续词法符号来恢复。
当面对真正的非法输入时,当前的规则无法继续下去,此时语法分析器将会向后查找词法符号,知道它认为自己已经完成重新同步时,它就返回原先被调用的规则。我们可以成为‘同步-返回’策略。有人称为“应急模式”,不过它的表现相当好。语法分析器知道自己无法使用当前规则匹配当前输入。它会持续丢弃后续词法符号,知道发现一个可以匹配本规则中断位置之后的某条自规则的词法符号。例如,如果在赋值语句中存在一个语法错误,那么语法分析器的做法就非常合理:丢弃后续的词法符号,直到发现一个分好或者其他的语句终结符为止。这种策略较为激进,但是十分有效。我们下面将要看到,这种基本策略作为后备方案,在启用之前,ANTLR 会试图在规则内部进行恢复。
重新同步集合是调用栈中所有规则的后续符号集合的并集。
例如,如果语法分析其分析到 atom 时报错,比如输入的是“[]”,就会在 atom 的时候报错。调用栈为[group,expr,atom]那么此时的后续符号集合则是{‘^’,’]’}。然后语法分析其就从 atom 的错误中恢复了,然后继续分析,分析 expr 发现缺少^从而产生错误,然后继续从符号集合中恢复。然后匹配 group 最后匹配成功。
恢复过程中,ANTLR 语法分析器会避免输出层叠的错误消息,对于每个语法错误,直到成功从错误中恢复,语法分析器才输出一条错误消息。所以本次语法解析过程,实际上是产生了两处解析错误:atom 和 expr
注意后续符号集合的生成是动态计算的。是调用栈中所有规则的后续符号的并集。
1 | group : '[' expr ']' | '(' expr ')'; |
从不匹配的词法符号中恢复
在语法分析的过程中,最常见的操作之一就是“匹配词法符号”。对于语法中的每个词法符号 T,语法分析器都会调用 match(T)。如果当前的词法符号不是 T,match()方法就会通知错误监听器,并试图重新同步。为完成同步,它有三种选择:- 移除一个词法符号;
1
2classDef: 'class' ID '{' member+ '}' //a class has one or more members
{System.out.println("class"+$ID.text);}考虑输入文本 class 9 T{int i;},语法分析器会删除 9,然后继续进行同一条规则的语法分析过程–匹配类的定义体。
- 补全一个词法符号;
1
2classDef: 'class' ID '{' member+ '}' //a class has one or more members
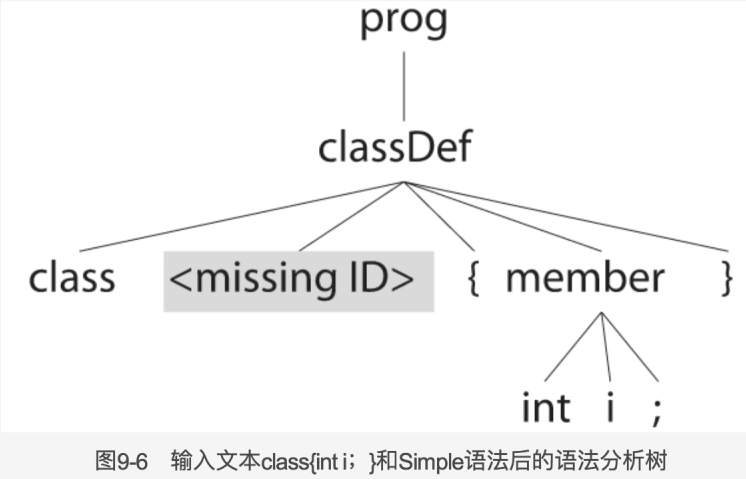
{System.out.println("class"+$ID.text);}考虑输入文本 class {int i;},语法分析器调用 match(ID),期望发现一个标识符,但实际上发现的却是{。这种情况下,语法分析器知道{是自己所期望的那个词法符号的下一个,因为在 classDef 规则中它位于 ID 之后。此时 match()方法可以假定标识符已经被发现并返回,这样,下一个 match(‘{‘)的调用就会成功。在忽略内嵌动作的前提下,这种方案表现得相当出色。但是,如果词法符号是 null,通过$ID.text 引用了缺失词法符号的打印语句就会引起一个异常。因此,错误处理器会创建一个词法符号,而非简单的假定该词法符号存在,详情参见 DefaultErrorStrategy 中的 getMissingSymbol()方法。新创建的词法符号具有语法分析器所期望的类型,以及和当前词法符号 LA(1)相同的行列位置信息。这个新创建的词法符号阻止了监听器和访问其中引用缺失词法符号时引发的异常。
从子规则的错误中恢复
在语法中手工插入一条空规则的引用,该规则包含特定的、能够在必要时触发错误恢复的动作。现在,ANTLR4 会在开始处和循环条件判定处自动插入同步检查,以避免集锦的恢复机制。- 子规则起始位置。在任意子规则的起始位置,语法分析器会尝试进行单词法符号移除。不过,和词法符号匹配不同的是,语法分析器不会尝试进行单词法符号补全。创建一个词法符号对 ANTLR 来说是很困难的,因为它必须猜测多个备选分支中的哪个会最终胜出。
- 子规则的循环条件判定位置。如果子规则是一个循环结构,即(…)*或(…)+,在遇到错误时,语法分析器会尝试进行积极的回复,使得自己留在循环内部。在成功地匹配到循环的某个备选分支之后,语法分析器会持续消费词法符号,直到发现满足下列条件之一的词法符号为止:
- 循环的另一次迭代
- 紧跟在循环之后的内容
- 当前规则的重新同步集合中的元素
例子:
考虑 Simple 语法的 classDef 规则中的 member+循环结构。如果我们手误多输入了’{‘,member+子规则会在进入 member 之前移除掉多余的那个词法符号。1
2
3
4
5> class T {{int i;}
> EOF
> line 1:9 extraneous input '{' expecting 'int'
var i
class T
捕获失败的语义判定
语义判定指定了一些必须在运行时为真的条件,以使得语法分析器能够通过这些条件的验证。如果一个判定结果为假,语法分析器会抛出一个 FailedPredicateException 异常,该异常会被当前规则的 catch 语句捕获。语法分析器随机报告一个错误,并运行通用的同步-返回恢复机制。1
2
3
4
5vec4: '[' ints[4] ']';
ints[int max]
locals [int i=1]
: INT(',' {$i++;} {$i<=max}? INT)*
;下列测试给出的整数过多,于是我们看到了一个错误消息,以及错误恢复的过程,在这个过程中,多余的逗号和整数被丢弃了:
1
2
3> [1,2,3,4,5,6]
> EOF
> line 1:9 rule ints failed predicate: {$i<=max}?有时候我们输入的结构语法上是有效的,但是在语义上是无效的,这是,语义判定就不适用了。例如有种语言,要求变量不能被赋值 0.这意味“assignment x =0;”在语法上有效,在语义上无效。
较好的解决办法是手工输出一个错误,然后令语法分析器按照正确的语法继续继续进行匹配。1
2
3assign
: ID '=' v=INT {$v.int>0}? ';'
{if ($v.int==0) notifyListeners("values must be > 0");}错误恢复机制的防护措施
ANTLR 的语法分析器具有内置的防护措施,以保证错误回复过程正常结束。如果我们在相同的语法分析位置,遇到了相同的输入情况,语法分析器会在尝试进行恢复之前强制消费一个词法符号。1
2
3
4
5
6
7> class T {
> int int x;
> }
> EOF
> line 2:6 no viable alternative at input 'intint'
> var x
> class TclassDef 规则调用了三次 member。其中,第一个 member 没有匹配到任何内容,第二个 member 匹配到了多余的 int。第三次匹配 member 的尝试正确地匹配到了“int x;”序列。
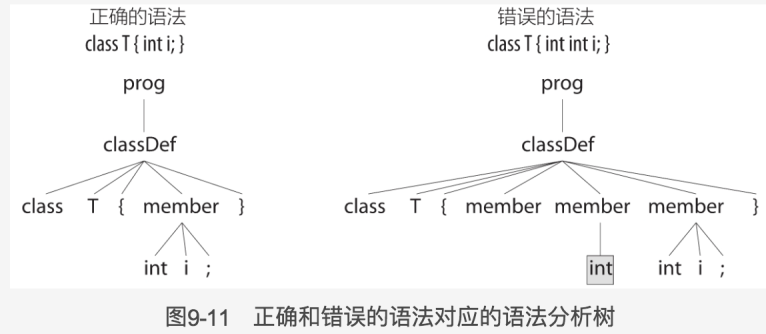
简单地抛出一个异常以启用基本的同步-返回机制
当面对真正的非法输入时,当前的规则无法继续下去,此时语法分析器将会向后查找词法符号,知道它认为自己已经完成重新同步时,它就返回原先被调用的规则。我们可以成为‘同步-返回’策略。有人称为“应急模式”,不过它的表现相当好。语法分析器知道自己无法使用当前规则匹配当前输入。它会持续丢弃后续词法符号,知道发现一个可以匹配本规则中断位置之后的某条自规则的词法符号。例如,如果在赋值语句中存在一个语法错误,那么语法分析器的做法就非常合适。
勘误备选分支
一些语法错误十分常见,以至于对它们进行特殊处理是值得的。
1 | stat: fcall ';'; |
修改 ANTLR 的错误处理策略
默认的错误处理机制表现出色,不过我们还是会遇到一些非典型的,需要修改默认机制的场景。首先,我们希望关闭某些默认的错误处理功能,他们会带来额外的运行负担。其次,我们可能希望语法分析器在遇到第一个语法错误时就退出。这种情况是,当处理类似 bash 的命令行输入时,从错误中回复是毫无意义的。我们不能一意孤星地执行有风险的命令,因此语法分析器可以一遇到问题就退出。探究错误处理策略,不妨看一下 ANTLRErrorStratege 接口及实现类 DefaultError-Strategy,该类完成了全部的默认错误处理工作。利用 ANTLRErrorListener 和 ANTLRErrorStrategy 接口,我们能够非常灵活地指定错误消息的输出位置、错误消息的内容以及语法分析器从错误中恢复的方法。
在语法分析过程中执行自身的逻辑代码
在之前的学习中,我们的程序逻辑代码都是与语法分析树遍历器分离的,这意味着我们的代码总是在语法分析完成之后执行。在接下来的几节(属性和动作、使用语义判定修改语法分析过程、掌握词法分析的“黑魔法”)中我们可以看到,一些语言类应用程序需要在语法分析的过程中执行自身的逻辑代码。
属性和动作
通常我们应当避免将语法和应用程序的逻辑代码纠缠在一起。不包含动作的语法更容易阅读,不会绑定到特定的目标语言和程序上。尽管如此,内嵌的动作仍然是有用的,原因有如下三个:
- 简便: 有时,使用少量的动作,避免创建一个监听器或者访问器会使事情变得更加简单。
- 效率:在资源紧张的程序中,我们可能不想把宝贵的时间和内存浪费在简历语法分析树上。
- 待判定的语法分析过程:在某些罕见情况下,我们必须依赖从之前的输入流中获取的数据才能正常第进行语法分析过程。一些语法需要建立一个符号表,以便在未来根据情况差异化地识别输入的文本。
动作就是使用目标语言编写的、放置在{}中的任意代码块。我们可以在动作中编写任意代码,只要它们是合法的目标语言语句。动作的典型用法是操纵词法符号和规则引用的属性。例如,我们可以读取一个词法符号对应的文本或者整个规则匹配的文本。通过从词法符号和规则引用中获取的数据,我们就可以打印结果或者执行任意计算。规则允许参数和返回值,因此我们可以在规则之间传递数据。
添加动作
定义 header 和 members
这些动作可以位于规则内,也可以位于规则外。header 用于向自动生成的语法分析器和词法分析器中注入 package 或 import 语句。members 用于向自动生成的语法分析器和词法分析器中注入字段(成员变量)和方法(成员函数)。下面显示了注入代码片段的位置。1
2
3
4
5<header>
public class <grammarName>Parser extends Parser {
<members>
...
}我们使用@header{}和@members{}来注入代码。{}内的代码,将出现在语法和词法解析器中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19grammar Expr;
//定义了语法和词法解析器所属的包,并导入了java.util包
@header {
package tools;
import java.util.*;
}
//新增了语法和词法解析器中的字段(成员变量)memory和方法eval()。
@members {
Map<String, Integer> memory = new HashMap<String, Integer>();
int eval (int left, int op, int right) {
switch (op) {
case MUL: return left * right;
case DIV: return left / right;
case ADD: return left + right;
case SUB: return left - right;
}
return 0;
}
}在规则中嵌入动作
动作执行时机是它前面的语法元素之后。本例中,动作出现在备选分支的末尾,因此它们会在语法分析器匹配到整个语句之后被执行。1
2
3
4stat: e NEWLINE {System.out.println($e.v);}
| ID '=' e NEWLINE {memory.put($ID.text, $e.v);}
| NEWLINE
;- returns 定义了返回值 v,且类型为 int。通过$e.v 可以引用 e 规则的返回值。
- a,b,op 都是标记,它们是对=右侧的引用。使用标记可以方便在动作中操作各种值。ANTLR 通过规则上下文对象来实现语法分析树的节点,每次规则调用都会新建并返回一个规则上下文对象。自然地,规则上下文对象非常适合放置与特定规则相关的数据实体。EContext 的第一部分如下所示:
1
2
3
4
5
6
7
8
9
10
11e returns [int v]
: a=e op=('*'|'/') b=e {$v = eval($a.v, $op.type, $b.v);}
| a=e op=('+'|'-') b=e {$v = eval($a.v, $op.type, $b.v);}
| INT {$v = $INT.int;}
| ID
{
String id = $ID.text;
$v = memory.containsKey(id) ? memory.get(id) : 0;
}
| '(' e ')' {$v = $e.v;}
;1
2
3
4
5
6
7
8
9public static class EContext extends ParserRuleContext{
public int v; //规则e的返回值
public EContext a; //规则引用e上的标记a
public Token op; //类似(‘*’|‘/’)的运算符子规则上的标记
public EContext b; //规则引用e上的标记b
public Token INT; //第三个备选分支引用的INT
public Token ID; //第四个备选分支引用的ID
public EContext e; //e的调用过程对应的上下文对象的引用
}
访问词法符号和规则的属性
此节中可以看到如何定义和引用规则的参数和返回值。
原始规则
1 | grammar CSV; |
改造后的规则
1 | /* 由规则"file: hdr row+ ;"衍生而来 */ |
输入如下数据
1 | User, Name, Dept |
输出解析结果
1 | header: 'User, Name, Dept' |
关键字识别
此节中我们将看到如何使用词法符号属性,text 和 type。
1 | grammar Keywords; |
使用语义判定修改语法分析过程
在上节中,内嵌动作仅仅是计算一些值或者打印结果。但是,某些情况下使用内嵌动作类修改语法分析过程是正确识别某些编程语言语句的唯一方案。本章我们学习一种特殊的动作{…}?,成为语义判定,它允许我们在运行时选择性地关闭部分语法。判定本身就是布尔表达式,它会减少语法分析器的在语法分析过程中可选项的数量。适当地减少可选项的数量会增强语法分析器的性能。在词法规则中使用判定,一样会拖慢词法分析器。
语义判定可以在两种常见情况下发挥作用。
第一,我们可能需要语法分析器处理同一门编程语言稍有差异的多个版本。语义判定允许我们通过命令行参数或者其他动态机制,在运行时选择所使用的方言。
第二,应用场景包含处理语法的歧义性。在某些编程语言中,相同的语法结构具有不同的含义,此时判定机制提供了一种方法,让我们能够在对相同输入文本的不同解释中做出选择。
在语法规则中加入判定
1
2
3
4
5
6
7
8
9
10
11
12
13
14grammar Enum;
@parser::members {public static boolean java5;}
prog: (stat
| enumDecl
)+
;
stat: id '=' expr ';' {System.out.println($id.text+"="+$expr.text);};
expr: id | INT;
enumDecl: {java5}? 'enum' name=id '{' id (',' id)* '}'
{System.out.println("enum "+$name.text);}
;
ENUM: 'enum';
ID: [a-zA-Z]+;判定可以开启和关闭任何在通过判定后能被匹配的规则。
下面这样写,一样是正确的。1
prog : ({java5}? enumDecl| stat)+;
在词法规则中加入判定
1
2
3
4
5enumDecl: 'enum' name=id '{' id (',' id)* '}'
{System.out.println("enum "+$name.text);}
;
ENUM: 'enum' {java5}? ;//必须放置在ID规则之前
ID: [a-zA-Z]+;需要注意的是,判定出现在词法规则的右侧,而非像文法规则一样的左侧。这是由于在语法分析中,语法分析器会对之后的内容进行预测,因此需要在匹配备选分支之前进行判定。而词法分析器不进行备选分支的预测。它们仅仅寻找最长的匹配文本,然后在发现整个词法符号后做出决策。当 java5 为假时,该判定关闭了 ENUM 规则。当它为真时,ENUM 和 ID 同时匹配了字符序列 e-n-u-m,此时该输入存在歧义。ANTLR 总是通过选择位置靠前的规则来解决词法歧义问题,也就是这里的 ENUM。
识别歧义文本
1
2
3
4
5
6/** 前两个备选分支中使用了理想化的判定作为区分这两种情况的Demo **/
expr: {<<isfunc(ID)>>}? ID '(' expr ')' //一个参数的函数调用
| {<<istype(ID)>>}? ID '(' expr ')' //构造器风格的对expr的转换
| INT //整数常量
| ID //标识符
;当我们使用这份带判定的语法再次进行测试时,输入”f(i);”被正确地解释成了函数调用表达式,而非声明。输入”T(i);”也被正确解释成了声明。
1
2
3
4
5
6
7
8
9
10
11decl: ID ID
| {istype()}? ID '(' ID ')'
;
expr: INT
| ID
| {!istype()}? ID '(' expr ')'
;
@parser::members {
Set<String> types = new HashSet<String>() {{add("T");}};
boolean istype() {return types.contains(getCurrentToken().getText());}
}
掌握词法分析的“黑魔法”
将词法符号送入不同通道
将空格和回车送入不同通道,而正常的词法符号仍然位于默认的 0 通道。
1
2WS : [\t\n\r]+ -> channel(1);
SL_COMMENT : '//' .*? '\n' -> channel(2);访问隐藏通道
通过继承监听器,在方法中可以调用 BufferedTokenStream.getHiddenTokensToRight()得到隐藏 channel,进而可以访问 channel 中的 Token 的 text 进行改造。
上下文相关的词法问题
字符流中的孤岛
对 XML 进行语法分析和词法分析
语法参考
语法词汇表
- 注释
ANTLR 支持单行、多行注释。
1 | grammar T; |
- 标识符
词法符号名和词法规则名总是以大写字母开头。文法规则总是以小写字母开头。首字母之后的字符可以是大小写字符、数字和下划线。
tokens{LEXSYMBOL,ASYMBOL,BSYMBOL} //词法符号名
LEXSYMBOL: [0-9a-z]* //词法规则
1 | ID,LPAREN,RIGHT_CURLY //词法符号和词法规则名 |
ANTLR是支持中文等unicode的。同时也支持非unicode,需要在使用ANTLR工具中使用-encoding选项,以便正确读字符。文本常量
ANTLR 不区分字符常量和字符串常量,所有的文本常量都是由单引号括起来的字符串,如’;’、’if’、‘<’。文本常量不支持正则表达式。文本常量也可以是 Unicode 转义序列’\u00E8’,或者常见转义序列’\n’、’\r’等。
ANTLR 生成的识别器假定语法中的字符都是 Unicode 字符,ANTLR 运行库根据目标语言对输入文件的编码做出假设,例如对于 Java 运行库假定输入文件为 UTF-8 编码。(Unicode 是字符集每个字符一个码,UTF-8 定义了如何使用二进制存储这个码,比如变长或定长,使用 1 个字节还是多个字节)动作
动作是使用目标语言编写代码块,由花括号包围的任意文本。内嵌代码可以出现在以@header 和@members 命名的动作、词法和文法规则、指定异常捕获区、文法规则的属性区域,以及一些规则元素的选项。关键字
- 不要使用 ANTLR 保留字,ANTLR 语法中的保留字列表:import、tokens、options 等。
- 不要使用 rule 这个关键字。rule 虽然不是关键字也要避免将它作为规则或者备选分支,因为这样会使得自动生成的 RuleContext 上下文对象与内之类冲突。
- 不要使用目标语言中的关键字作为词法符号、标签或者规则名。例如,if 规则会生成 if()函数。
语法结构
1 | grammar Name |
文法规则
1 | grammar Name |
1.#标签的作用是为每个备选分支都生成一个监听器。不然的话,就只为规则生成监听器。所以标签的名要求不能与已有标签名或者规则名冲突。
2.ANTLR 为每个规则生成规则上下文对象,并附带访问方法。NameContext 对象里面包含访问 Econtext 的方法。
3.为规则 a 增加标签 value
4.规则元素