SQLite相关
Lemon
The author of Lemon and SQLite (Hipp) reports that his C programming skills were greatly enhanced by studying John Ousterhout’s original source code to Tcl.
SQLite 整体流程
在 shell.c 的 shell_exec()函数中可以看到,一般先执行 sqlite3_prepare_v2()得到 sqlite3_stmt *pSelect;然后再执行 rc = sqlite3_step(pSelect)得到结果;最后执行 sqlite3_finalize()
1 | sqlite3_stmt *pStmt; /* Statement to execute. */ |
sqlite3_prepare_v2
1.1
prepare.c->sqlite3_prepare_v2->sqlite3LockAndPrepare->sqlite3Prepare(const char *zSql,sqlite3_stmt **ppStmt,...)输入的 UTF-8 encoded SQL zSql 被编译为一个 prepared statement 指针 ppStmt 并返回。同时内部初始化 Parse。- 1.1.1
Parse *pParse = sqlite3StackAllocZero(db, sizeof(\*pParse));Parse 是一个 SQL parser 上下文,它从 parser 传递到 sql 解析相关内容到所有 parser action routine。相当于是解析过程中的一个全局变量,但是并未声明为全局变量,而是以入参方式进行传递。
Parse 的主要成员包括1
2
3
4
5sqlite3 *db; /* The main database structure */
Vdbe *pVdbe; /* An engine for executing database bytecode */
Token sLastToken; /* The last token parsed */
Table *pNewTable; /* A table being constructed by CREATE TABLE */
table,column,lock等相关信息 - 1.1.2
sqlite3RunParser(pParse, zSqlCopy, &zErrMsg);调用 sqlite3RunParser()对 zSqlCopy 进行解析。内部完成对 pParse->pVdbe 初始化赋值 - 1.1.3
*ppStmt = (sqlite3_stmt*)pParse->pVdbe;
- 1.1.1
1.2
tokenize.c->sqlite3RunParser(Parse *pParse, const char *zSql, char **pzErrMsg)对 zSql 指向 SQL 字符串,对其进行解析,pParse 作为解析上下文被传入,函数将返回 SQLITE_的 status code。1.2.1
pEngine = sqlite3ParserAlloc((void*(*)(size_t))sqlite3Malloc)创建解析器 pEngine, LEMON-generated LALR(1) parser。1.2.2
1
2
3
4
5
6
7
8
9while( !db->mallocFailed && zSql[i]!=0 ){
pParse->sLastToken.z = &zSql[i];
pParse->sLastToken.n = sqlite3GetToken((unsigned char\*)&zSql[i],&tokenType);
....
switch( tokenType ){
case TK_SPACE: break;
case TK_SEMI: break;
default: sqlite3Parser(pEngine, tokenType, pParse->sLastToken, pParse);
}循环处理 SQL,sqlite3GetToken()将从指定数组位置开始解析,token 类型解析后存入 tokenType,token 长度最为函数返回值。
然后,switch 语句根据 token 类型进行处理,一般都会进入 default 中。里面调用 sqlite3Parser(),将待解析的 token,pParse 解析上下文传递给解析器 pEngine。经过若干次循环,以及解析递归,在 sqlite3Parser()里完成对 pParse->pVdbe 初始化赋值。
1.3
parse.c->sqlite3Parser()
在 sqlite3Parser()里会读入 token,并对 token 组成的字符串进行分析匹配到合适的语法规则,然后调用相应的动作。语法规则和动作定义在 parse.y 中,动作中一般会调用 build.c,select.c 中定义好的动作函数,来进行 vdbe 初始化和字节码生成等操作。1
2
3
4
5
6void sqlite3Parser(
void *yyp, /* The parser */
int yymajor, /* The major token code number */
sqlite3ParserTOKENTYPE yyminor /* The value for the token */
sqlite3ParserARG_PDECL /* Optional %extra_argument parameter */
)关键逻辑,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16do{
yyact = yy_find_shift_action(yypParser,(YYCODETYPE)yymajor);
if( yyact<YYNSTATE ){
assert( !yyendofinput ); /* Impossible to shift the $ token */
yy_shift(yypParser,yyact,yymajor,&yyminorunion);
yypParser->yyerrcnt--;
yymajor = YYNOCODE;
}else if( yyact < YYNSTATE + YYNRULE ){
yy_reduce(yypParser,yyact-YYNSTATE);
}else{
assert( yyact == YY_ERROR_ACTION );
yy_syntax_error(yypParser,yymajor,yyminorunion);
yy_destructor(yypParser,(YYCODETYPE)yymajor,&yyminorunion);
yymajor = YYNOCODE;
}
} while(yymajor!=YYNOCODE && yypParser->yyidx>=0)- 1.3.1
parse.y
中定义的 DROP TABLE 和 SELECT 规则如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16////////////////////////// The DROP TABLE /////////////////////////////////////
//
cmd ::= DROP TABLE ifexists(E) fullname(X). {
sqlite3DropTable(pParse, X, 0, E);
}
%type ifexists {int}
ifexists(A) ::= IF EXISTS. {A = 1;}
ifexists(A) ::= . {A = 0;}
//////////////////////// The SELECT statement /////////////////////////////////
//
cmd ::= select(X). {
SelectDest dest = {SRT_Output, 0, 0, 0, 0};
sqlite3Select(pParse, X, &dest);
sqlite3SelectDelete(pParse->db, X);
}- 1.3.2
parse.c->yy_reduce(yyParser *yypParser, int yyruleno)完成一个 reduce 动作和相关 shift 动作。
yypParser 是解析器,yyruleno 是规则号。这里关键逻辑是,根据规则号调用相应的处理逻辑,如下是 DROP TABLE 的处理逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16switch( yyruleno ){
...
case 107: /* cmd ::= DROP TABLE ifexists fullname */
{
sqlite3DropTable(pParse, yymsp[0].minor.yy259, 0, yymsp[-1].minor.yy4);
}
break;
case 112: /* cmd ::= select */
{
SelectDest dest = {SRT_Output, 0, 0, 0, 0};
sqlite3Select(pParse, yymsp[0].minor.yy387, &dest);
sqlite3SelectDelete(pParse->db, yymsp[0].minor.yy387);
}
break;
...
}- 1.3.1
1.4 代码生成器
- 1.4.1 `build.c->sqlite3DropTable(Parse *pParse, SrcList *pName, int isView, int noErr)` 这里是根据 pName 中的表名,来将表从系统中删除。关键逻辑这里根据 pParse 解析上下文来获得一个 vdbe,然后开始生成字节码通过 sqlite3VdbeAddOp4()函数。将操作指令载入 v 指向的 vdbe 中。最终在 在 sqlite3_prepare_v2 产生的结果 sqlite3_stmt \*\*ppStmt 中返回。 - 1.4.2 `select.c->sqlite3Select()` 这里产生 select 的字节码,包括各种 from,group by,limit 等。当处理 where 语句是调用 sqlite3WhereBegin(),这里做查询优化,sqlite3WhereEnd()负责优化后的清理工作。 - 1.4.2.1 ‘where.c->sqlite3WhereBegin()’ sqlite3WhereBegin 函数中调用 exprAnalyzeAll 分析 Where 语法树,嵌套循环调用 bestBtreeIndex 函数计算每种查询策略代价,选取最优代价的策略生成 VDBE OPCode。 - `初始化` 为返回值 WhereInfo 初始化及分配内存空间,一次分配 WhereInfo 中的 a[]、WhereClause 及 WhereMaskSet。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33/* Generate code to remove the table from the master table
** on disk.
*/
v = sqlite3GetVdbe(pParse);
if( v ){
Trigger *pTrigger;
Db *pDb = &db->aDb[iDb];
sqlite3BeginWriteOperation(pParse, 1, iDb);
sqlite3FkDropTable(pParse, pName, pTab);
/* Drop all SQLITE_MASTER table and index entries that refer to the
** table. The program name loops through the master table and deletes
** every row that refers to a table of the same name as the one being
** dropped. Triggers are handled seperately because a trigger can be
** created in the temp database that refers to a table in another
** database.
*/
sqlite3NestedParse(pParse,
"DELETE FROM %Q.%s WHERE tbl_name=%Q and type!='trigger'",
pDb->zName, SCHEMA_TABLE(iDb), pTab->zName);
sqlite3ClearStatTables(pParse, iDb, "tbl", pTab->zName);
if( !isView && !IsVirtual(pTab) ){
destroyTable(pParse, pTab);
}
/* Remove the table entry from SQLite's internal schema and modify
** the schema cookie.
*/
if( IsVirtual(pTab) ){
sqlite3VdbeAddOp4(v, OP_VDestroy, iDb, 0, 0, pTab->zName, 0);
}
sqlite3VdbeAddOp4(v, OP_DropTable, iDb, 0, 0, pTab->zName, 0);
sqlite3ChangeCookie(pParse, iDb);
}- `whereSplit(pWC, pWhere, TK_AND)` 初始化 WhereClause pWC,调用 whereSplit 函数进行分解 Where 语句中以 AND 操作符分割的子语句。1
2
3
4
5
6
7db = pParse->db;
nByteWInfo = ROUND8(sizeof(WhereInfo)+(nTabList-1)*sizeof(WhereLevel));
pWInfo = sqlite3DbMallocZero(db,
nByteWInfo +
sizeof(WhereClause) +
sizeof(WhereMaskSet)
);- `exprAnalyzeAll()` 调用 exprAnalyzeAll 函数分析所有的子表达式,处理前面查询语句的几种查询优化处理方法,例如 BETWEEN、同属性多个 OR 连接、LIKE 语句等的处理。 - `bestBtreeIndex()`?? `bestBtreeIndex(pParse, pWC, pTabItem, mask, notReady, pOrderBy,pDist, &sCost);`将计算的代价结果存入 sCost 中。计算对当前循环的表查询策略的代价,通过分析能否使用索引、记录数量、排序等因素估算查询开销代价。 为某个特定的表寻找最佳查询计划。确定最好的查询计划和成本, 写入最后一个传入的 WhereCost 对象参数。 分析影响查询策略代价的因数计算查询开销,因素主要包括: - 能否使用索引; - 记录数量; - 是否排序; - 查询条件的类型; - 如果有 INDEX BY 子句 (pSrc->pIndex) 附加到 SQL 语句中, 此函数只考虑使用指定的索引。如果没有这样的计划找到,那么返回的成本就是 SQLITE_BIG_DBL。 - 如果没有索引子句 (pSrc->notIndexed!=0) 附加到的表中的 SELECT 语句,认为没有索引。然而,所选的计划仍然可以利用内置的 rowid 主键索引。 - `codeOneLoopStart()`?? 调用 codeOneLoopStart 函数,生成查询处理 OPCode,针对 for 循环中的每次迭代生成单个虚拟机程序的嵌套循环,并且根据优化分析得到的结果针对 5 种查询策略生成每层循环不同的 OPCode。 根据五种查询策略生成OPCode,包括: RowId等值查询; RowId范围查询; 使用索引等值或范围查询; OR查询; 全表扫描; 基于虚表(Virtual Table)的扫描。 - 虚表等值处理1
2
3
4initMaskSet(pMaskSet);
whereClauseInit(pWC, pParse, pMaskSet, wctrlFlags);
sqlite3ExprCodeConstants(pParse, pWhere);
whereSplit(pWC, pWhere, TK_AND); /* IMP: R-15842-53296 */- RowId等值查询1
2
3
4
5
6
7
8if( (pLevel->plan.wsFlags & WHERE_VIRTUALTABLE)!=0 ){
/* Case 0: The table is a virtual-table. Use the VFilter and VNext to access the data.
表是一个虚拟表。使用VFilter和VNext访问数据
*/
......
sqlite3VdbeAddOp2(v, OP_Integer, pVtabIdx->idxNum, iReg);
sqlite3VdbeAddOp2(v, OP_Integer, j-1, iReg+1);
sqlite3VdbeAddOp4(v, OP_VFilter, iCur, addrBrk, iReg, pVtabIdx->idxStr, pVtabIdx->needToFreeIdxStr ? P4_MPRINTF : P4_STATIC);- RowId非等值扫描:1
2
3
4
5
6
7
8
9
10
11if( pLevel->plan.wsFlags & WHERE_ROWID_EQ ){
/* Case 1: We can directly reference a single row using an
** equality comparison against the ROWID field. Or
** we reference multiple rows using a "rowid IN (...)" construct.
** 可以直接引用一个单行对ROWID字段使用相等的比较。
** 或者使用引用多个行“rowid(…)IN”结构。
*/
......
sqlite3VdbeAddOp2(v, OP_MustBeInt, iRowidReg, addrNxt);
sqlite3VdbeAddOp3(v, OP_NotExists, iCur, addrNxt, iRowidReg);
sqlite3ExprCacheStore(pParse, iCur, -1, iRowidReg);- 使用索引的范围或等值查询1
2
3
4
5
6else if( pLevel->plan.wsFlags & WHERE_ROWID_RANGE ){
/* Case 2: We have an inequality comparison against the ROWID field.
对ROWID字段非等值的比较
*/
......
sqlite3VdbeAddOp3(v, aMoveOp[pX->op-TK_GT], iCur, addrBrk, r1);- OR查询1
2
3
4
5
6
7
8
9
10else if( pLevel->plan.wsFlags & (WHERE_COLUMN_RANGE|WHERE_COLUMN_EQ) ){
/* Case 3: A scan using an index.
where子句可能有0个或者多个相等关系("==" or "IN" )涉及到N个最左连接索引它可能也有不等关系(>, <, >= or <=)在索引集中紧跟着N相等关系。只有最右连接集才可以成为相等,剩余的必须用于 "==" and "IN" 。
例如以(x,y,z)建立索引。下面所有的子句都是最优的。
x=5
** x=5 AND y=10
** x=5 AND y<10
** x=5 AND y>5 AND y<10
** x=5 AND y=5 AND z<=10**- 全表查询1
2
3if( pLevel->plan.wsFlags & WHERE_MULTI_OR ){
/* Case 4: Two or more separately indexed terms connected by OR
**两个或两个以上的独立索引术语或连接1
2
3
4
5
6
7
8
9
10
11
12
13else{
/* Case 5: There is no usable index. We must do a complete scan of the entire table.
没有可用的索引。我们必须完整的扫描整个表。
*/
static const u8 aStep[] = { OP_Next, OP_Prev };
static const u8 aStart[] = { OP_Rewind, OP_Last };
assert( bRev==0 || bRev==1 );
assert( omitTable==0 );
pLevel->op = aStep[bRev];
pLevel->p1 = iCur;
pLevel->p2 = 1 + sqlite3VdbeAddOp2(v, aStart[bRev], iCur, addrBrk);
pLevel->p5 = SQLITE_STMTSTATUS_FULLSCAN_STEP;
}
2.
vdbeapi.c->sqlite3_step()- 2.1
vdbeapi.c->sqlite3_step()->sqlite3Step()->sqlite3VdbeExec(Vdbe *p)
sqlite3_step 将 sqlite3_prepare_v2 产生的结果 sqlite3_stmt **ppStmt,转换为 Vdbe *p。然后继续出。
主要逻辑如下先执行初始化,然后开始循环处理字节码并在 switch 中进行对应类型字节码的处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41SQLITE_PRIVATE int sqlite3VdbeExec(Vdbe *p){
int pc=0; /* The program counter */
Op *aOp = p->aOp; /* Copy of p->aOp */
Op *pOp; /* Current operation */
int rc = SQLITE_OK; /* Value to return */
sqlite3 *db = p->db; /* The database */
u8 resetSchemaOnFault = 0; /* Reset schema after an error if positive */
u8 encoding = ENC(db); /* The database encoding */
Mem *aMem = p->aMem; /* Copy of p->aMem */
Mem *pIn1 = 0; /* 1st input operand */
Mem *pIn2 = 0; /* 2nd input operand */
Mem *pIn3 = 0; /* 3rd input operand */
Mem *pOut = 0; /* Output operand */
int iCompare = 0; /* Result of last OP_Compare operation */
int *aPermute = 0; /* Permutation of columns for OP_Compare */
i64 lastRowid = db->lastRowid; /* Saved value of the last insert ROWID */
for(pc=p->pc; rc==SQLITE_OK; pc++){ //for循环中逐条执行指令,pc是指令计数器
assert( pc>=0 && pc<p->nOp );
if( db->mallocFailed ) goto no_mem;
switch( pOp->opcode ){
//switch语句,每一个case都是在VDBE里执行一个单独的指令,例如下面
/* Opcode: Not P1 P2 * * *
**
** Interpret the value in register P1 as a boolean value. Store the
** boolean complement in register P2. If the value in register P1 is
** NULL, then a NULL is stored in P2.
*/
case OP_Not: { /* same as TK_NOT, in1, out2 */
pIn1 = &aMem[pOp->p1];
pOut = &aMem[pOp->p2];
if( pIn1->flags & MEM_Null ){
sqlite3VdbeMemSetNull(pOut);
}else{
sqlite3VdbeMemSetInt64(pOut, !sqlite3VdbeIntValue(pIn1));
}
break;
}
}
}
}- 2.1
- 3.
vdbeapi.c->sqlite3_finalize(sqlite3_stmt *pStmt)
这里将销毁由 sqlite3_compile()创建的虚拟机,pStmt->pVdbe 指向了这个虚拟机。sqlite3VdbeFinalize(v)具体执行了销毁操作。释放掉 pVdbe 指向的内存。
后端
源代码编译和调试
通过修改 3.7 版本的 makefile 中sqlite3$(TEXE) 可以使用 gdb 断点调试在 sqlite3.c 中
1 | sqlite3$(TEXE): $(TOP)/src/shell.c sqlite3.c |
1 | CREATE INDEX index_dept ON DEPARTMENT (DEPT); |
OS 层
sqlite3.h定义了主要的数据结构
sqlite3_vfs: 定义了 vps 的名字,核心方法:比如创建文件,删除文件等。
sqlite3_io_methods: 定义了操作文件的方法,比如读文件,写文件等。
sqlite3_file:代表一个打开了的文件,由 sqlite3_vfs 中的 XOpen 方法返回。sqlite3_file 内部存储一个指向 sqlite3_io_methods 的指针。test_demovfs.c是一个 sqlite3_vfs 实现类的样例。C 语言中通过给结构体的函数指针赋值,来完成接口和实现类的连接。
1 | static int demoDelete(sqlite3_vfs *pVfs, const char *zPath, int dirSync){ |
Pager 层
Storage
Database File Structure
- SQLite 将每个 database file 分成了若干个固定大小的区域叫 page。这样 database file 就变成了数组,如下:
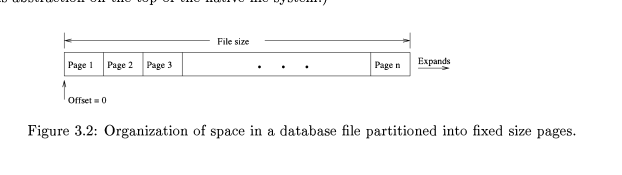
- page size 默认为 1024 bytes。这个值可以在编译时指定或者在创建第一个 table 之前使用命令
page_size pragma - page type.包含四中类型:free,tree,pointer-map,lock-byte.
- 数据库的元数据存储在第一个 page,其他 page 可以存储任意 page type 的数据。第一个 page 的结构如下

file header 中 1 前 100 字节存储 database file 结构信息,中间部分存储(master catalog table) B+树用于跟踪文件中的其他 page。header 部分的内容如下:
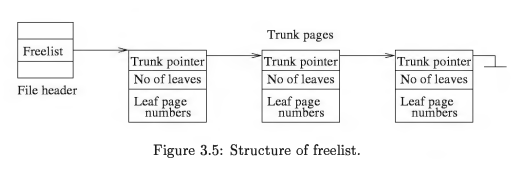
- freelist 数据结构。它按照如下结构组织数据。trunk pointer 用于指向下一个节点,number of leaves 用于存储叶子指针的数量,leaf page numbers 用于存储 leaf pages 的数量。当 page 不被使用时,SQLite 将它存储进 Freelist 并不换给文件系统。后面有信息 page 需求时,先从 freelist 中找到可用 page。如果想把 page 归还,可以使用 vacuum 命令(手动或自动)清空 page。
Journal File Structure
SQLite 使用三种日志文件:rollback journal, statement journal, master journal.
- Rollback journal.这个文件是临时文件,与 database file 位于同目录下。每次写事务时创建日志,每次结束时删除日志。

- segment header structure.
- 存储记录数,数据库初始 page 数量,sector size, page size,魔数(确认文件类型)等

- 日志文件可以被保留,日志文件需要包含有效的 segment header。
- SQLite 支持异步事务,也就是不强制刷新日志和 database file。这样性能好,但是不具备失败恢复性。
- 存储记录数,数据库初始 page 数量,sector size, page size,魔数(确认文件类型)等
- log record structure
- 数据结构如下:checksum 十分重要,因为在新建的文件中,log record 中的数据有可能是早先被删除的文件的内容,如果没有 checksum 做检查,那么脏数据就会被读取。这种将 page number 放在头部,checksum 放在尾部的方式,可以很好地在宕机后发现有问题的数据区域。因为一个区域的写往往是顺序的,如果头部和尾部是正确的,那么中间应该也是正确的。

- 数据结构如下:checksum 十分重要,因为在新建的文件中,log record 中的数据有可能是早先被删除的文件的内容,如果没有 checksum 做检查,那么脏数据就会被读取。这种将 page number 放在头部,checksum 放在尾部的方式,可以很好地在宕机后发现有问题的数据区域。因为一个区域的写往往是顺序的,如果头部和尾部是正确的,那么中间应该也是正确的。
- segment header structure.
- Statement journal
这个 Statement journal 被用来从 statement 失败中恢复数据库。当 Statement 执行成功后,这个文件被删除。
通过设置项,可以保留 Statement Journal。 - 多数据库事务日志和主日志
通常一个数据库只有一个 database file,一个 database file 对应一个事务。但是通过 attach 命令,可以将多个 database file 绑定在一个 sqlite 中。这样在一次事务执行过程中,可以操作多个 database file,每个 database file 都有自己单独的 rollback journal file。如果让多个子 journal file 保持全局原子性,需要使用 master journal。它位于 database file 同级目录,以-mj 结尾。
每个子 journal file,拥有 master journal 的名字。如下是子 journal file 的结构
日志管理
Journal 用于恢复,当事务失败或系统宕机时。每个数据库一个 Journal 文件,与数据库文件位于同目录,‘-journal’结尾命名。每当写事务开启时创建 journal,完成后关闭 journal。
SQLite 的使用的日志方式是最简单的且不是很高效。它在 page 级别粒度上记录旧值,使用 undo 方式恢复。SQLite 把将要被改变的数据所在的页的完整内容 copy 进 journal 中。journal 记录 database file 的尺寸在 journal segment header 中,当 journal 文件被创建是。如果 database file 被事务扩大了,那么 journal file 可以让 database file 回滚到原来大小。
- Journaled Page 跟踪:SQLite 使用内存 bit map 数据结构来跟踪哪个 page 被当前事务记录了日志。
- 不要给 database file 和 journal file 命名别名。
- WAL。在修改 database file 在 disk 生效之前,一定保证先把日志刷盘,以保证可以在宕机后修复。
- 异步事务模式。也就是在提交时不将 journal 文件刷盘,这样速度很快,但是没有恢复能力。临时数据库默认是异步事务,因为宕机时我们不需要恢复临时数据库。
- 子事务管理。每个 Statement 子事务通过用户事务获取锁,它并不 刷盘,因为它不承担恢复的责任。一个 log record 写入 Statement journal 仅当在 Statement 执行前相应 page 已经写在了用户事务中。
事务管理
事务类型
几乎所有数据库系统都是用锁来控制并发,使用日志来恢复。一开始 DBMS 首先将修改写入日志的磁盘中,然后再修改数据。当宕机发生时,撤销未完成的事务,重做已完成的事务。
- 系统事务
SQLite 中读写数据都必须在事务中进行,但是不需要显示指明事务类型,SQLite 根据操作自行分辨。对于 SELECT 语句 SQLite 开始读事务,对于非 SELECT 语句 SQLite 开始读事务,再将读事务升级为写事务。一个 connection 可以同时执行多个 SELECT 语句,但是非 SELECT 在 connection 只能单个执行。也就是多个读事务+单个写事务可以并发执行在一个 connection 上,但多个写事务不行。
非 SELECT 语句被原子地执行,执行前 SQLite 获取锁,执行完成释放锁。 - 用户事务
默认的系统事务,在执行多个写操作时效率很低,因为每执行一个写操作都要操作日志和锁。这时可以使用用户事务BEGIN TRANSACTION和COMMIT来包含多个写操作,减少日志和锁操作。用户定义的事务只包含写操作,读操作仍然是独立的原来的自动提交。如果事务 abort,那么读到那些被事务更改的数据的读操作也将 abort。
SQLite 不支持嵌套事务。 - Savepoint
在用户事务中可以设置 savepoint,savepoint 是数据库那个时刻的所有数据,可用于回滚当事务失败时。1
2
3
4
5
6
7CREATE TABLE t1(a PRIMARY KEY, b);
BEGIN;
INSERT INTO t1 VALUES(1, 'one');
INSERT INTO t1 VALUES(2, 'two');
UPDATE t1 SET a = a + 10 //UPDATE操作违反了主键唯一性的约束,那么将产生一个冲突,UPDATE前默认创建了一个savepoint,可以用于回滚。当然也可以显示指定。使用`SAVEPOINT`
INSERT INTO t1 VALUES(3,null);
COMMIT;
Lock
数据库的锁是为了保证事务执行的隔离性,通过锁来实现事务访问的顺序性,进而实现了事务的隔离性。
SQLite 的锁是数据库级别的锁,将整个数据库锁住(也就是锁住那个数据库文件,SQLite 将一个库的所有内容存储在一个文件中)。SQLite 为了简化锁的复杂度,采取了严格要求并发程度的方式。它允许同一时间任意数量的读事务。但是同一时间只有一个写事务,没有其他读写事务。
为了实现事务访问的顺序性,需要使用两阶段锁。
Statement 子事务通过所在的父事务获取锁,所有锁持续被事务持有直到事务执行成功或者失败。
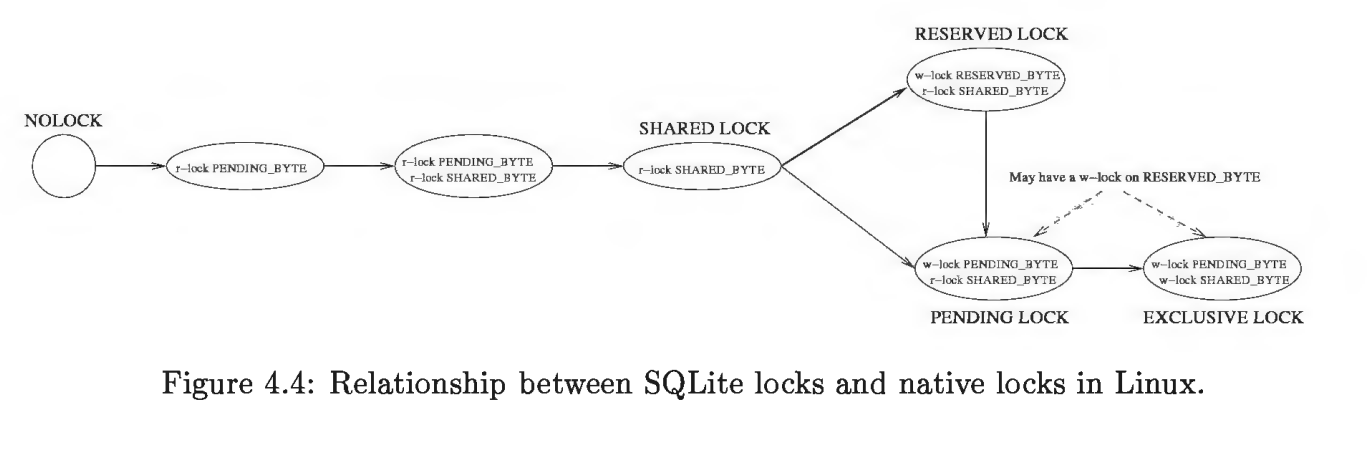
SQLite 在 unix 平台上的使用来自于 os_unix.c 文件的实现,但要实现对数据库的操作,其核心在于 SQLite 的锁机制。SQLite 采用粗放型的锁。当一个连接要写数据库时,所有其他的连接被锁住,直到写连接结束了它的事务。SQLite 有一个加锁表,来帮助不同的写数据库者能够在最后一刻再加锁,以保证最大的并发性。SQLite 使用锁逐步上升机制,为了写数据库,连接需要逐步地获得排它锁。对于 5 个不同的锁状态:未加锁(UNLOCKED)、共享(SHARED)、保留(RESERVED)、未决(PENDING)和排它(EXCLUSIVE)。每个数据库连接在同一时刻只能处于其中一个状态。每种状态(未加锁状态除外)都有一种锁与之对应。
锁类型:在 SQLite 中为了写数据库,连接需要逐步地获得排它锁。SQLite 有 5 个不同的锁:未加锁(NO_LOCK)、共享锁(SHARED_LOCK)、保留锁(RESERVED_LOCK)、未决锁(PENDING_LOCK)和排它锁(EXCLUSIVE_LOCK)。
NO_LOCK:最初的状态是未加锁状态,在此状态下,连接还没有存取数据库。当连接到了一个数据库,甚至已经用 BEGIN 开始了一个事务时,连接都还处于未加锁状态。
SHARED 锁:SHARED 锁意味着进程要读(不写)数据库。一个数据库上可以同时有多个进程获得 SHARED 锁,哪个进程能够在 SHARED_FIRST 区域加共享锁(使用 LockFileEx()LockFileEx()函数),即获得了 SHARED 锁。
RESERVED 锁: RESERVED 锁意味着进程将要对数据库进行写操作。一个数据库上同时只能有一个进程拥有 RESERVED 锁。RESERVED 锁可以与 SHARED 锁共存,并可以继续对数据库加新的 SHARED 锁。
PENDING 锁:PENDING LOCK 意味着进程已经完成缓存中的数据修改,并想立即将更新写入磁盘。它将等待此时已经存在的读锁事务完成,但是不允许对数据库加新的 SHARED LOCK(这与 RESERVED LOCK 相区别)。
EXCLUSIVE 锁:在此锁状态下,进程此时就可以自由地对数据库进行修改了,所有以前对缓冲区所做的修改都会被写到数据库文件。
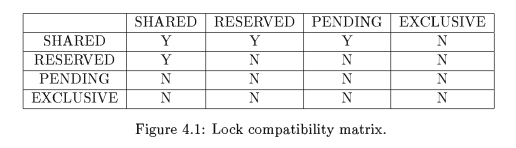
锁的兼容性和转换
下表中,每一行行首是指当前锁的类型,每一个列首是指申请的锁类型。Y 代表可以,N 代表不行。
每一个事务都需要在执行读写操作前获取合适的锁。这是 Pager 的责任从文件上获取锁。
5 种锁中,pending 是一种内部类型锁。pager 不能直接跟 lock management 申请 pending。pager 只能申请 exclusive,然后 lock management 根据情况,可能返回拒绝或 pending lock 或 exclusive lock。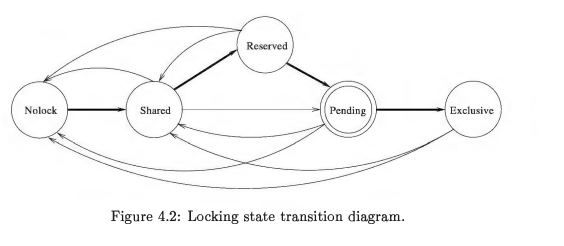
一次读事务,nolock-shared lock-no lock.
一次写事务,nolock-shared lock-reserved lock- pending lock - Exclusive lock
一次事务回滚,nolock-shared lock-pending lock-exclusive lock
锁的实现
SQLite 依赖 Linux 的的锁原语,fcnt()它可以提供读锁和写锁,并且指定锁定的文件中范围。
文件中的 512 字节用于锁。其中 510 字节用于 shared 锁和 exclusive 锁。fcntl 的读锁这 510 字节,则获取 shared 锁。写锁锁住 510,则获取 exclusive 锁。
reserved 锁,是第 511 字节。使用 fcntl()添加写锁。peding 锁在 512 字节,使用 fcntl()添加写锁。
这里的读锁为什么范围是 510 的原因是,windows 不支持读锁。那么使用一个大的范围,每个 bytes 单独设置一个写锁,可以支持 510 的写锁。那么这些写锁可以作为 sqlite 并发的读锁。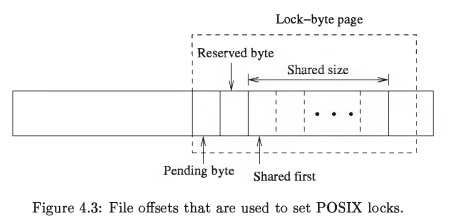
unixLock 方法
os_unix.c 文件
1 | static int unixLock(sqlite3_file *id, int eFileLock) //加锁逻辑 |
面对锁时进程,线程,事务,unixFile,unixInodInfo 之间的关系
Linux 操作系统中。 1.将锁与文件的 inode 联系在一起,而不是使用文件名,因为通过文件可以指向同一个 inode(因为符号链接,硬链接)。 2.锁的获取是通过文件描述符得到的,但是如果文件描述符指向相同的 inode,那么实际的效果还是在操作同一个锁。
因此,Linux 的这种机制,使得在同一个 process 下多个线程或 connection(transction)打开相同的文件时会出现问题,比因为对于系统来说它只按照 process+文件来区分锁的粒度。此时多个线程或 transaction 都在操作同一个锁.
所以,我们需要 unixInodeInfo 结构体在 process 存储文件锁的整体情况。一个 unixInodeInfo 对象代表一个位于 database file 的 SQLite 锁。一个 process 不能拥有多个指向相同文件的 unixInodeInfo 对象。因为一个 process 可以打开多个文件,所以使用 inodeList 来存储所有 unixInodeInfo 对象。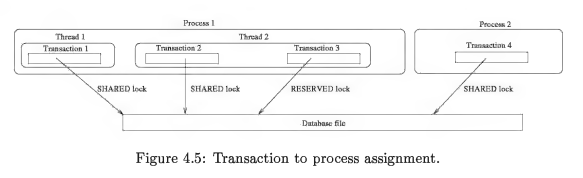
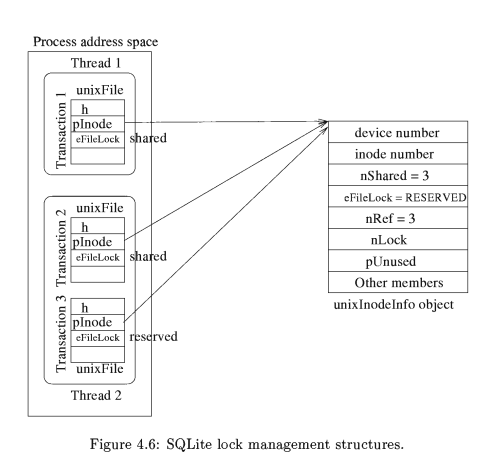
- unixInodeInfo
os_unix.c 文件unixInodeInfo结构体,存储了一个进程打开某个文件 iNode 的对应的锁的信息。当进程持有一个文件的 RESERVED 锁,线程如果申请 SHARED 锁,则该进程在 unixInodeInfo 中的 nShared 加 1。如果一个线程申请排它锁,进程则调用 fcntl 获取文件中的排它锁。
1 | struct unixInodeInfo { |
- unixFile
位于os_unix.c 文件,SQLite 使用 unixFile 来跟踪一个文件的打开实例。
1 | struct unixFile { |
多线程问题
- LinuxThreads 是按照线程区分 lock,不同线程之间不能覆盖 lock。NPTL(Native Posix Thread Library)从 3.7.0 开始支持的,同 Process 的线程之间可以相互覆盖 lock。
- 当一个线程关闭文件时,Linux 将删除 inode 上所有的锁,而不管具体是哪个线程的锁。SQLite 对此进行了优化,单个线程关闭文件时不会立刻删除所有的 lock,而是跟踪,等到 inode 上最后一个文件描述符被关闭时,才将所有文件描述符关闭并将 lock 释放掉。
API
unixLock包含了完整的锁状态转换和加锁。
1 | static int unixLock(sqlite3_file *id, int eFileLock) //加锁逻辑 |
unixFileLock是对 fcntl 和 sqlilte 区域锁实现的封装
1 | static int unixFileLock(unixFile *pFile, struct flock *pLock) |
unixUnlock是解锁
解开低等级锁,eFileLock 只能是 SHARED_LOCK 或 NO_LOCK。
1 | static int unixUnlock(sqlite3_file *id, int eFileLock){ |
Page 模块
Page 模块简介
Page 模块的作用是提供了更高层次访问数据库文件的接口,它将原本面向字节的文件操作转换成了面向 page 的文件操作。Tree 模块完全依赖于 page 来访问数据。Page cache 通过将数据放在内存,加快数据的访问,并负责内存和磁盘间的数据同步。同时 Page 模块对事务,日志,锁管理负责。其中锁管理和日志管理在 SQLite 的事务原子提交特性中起着关键作用。
它为每个打开的 database file 维护一个单独的 page cache。如果同一个进程打开 database file 多次,会创建多个 cache 出来。
源码阅读参考:https://blog.csdn.net/pfysw/article/details/79121815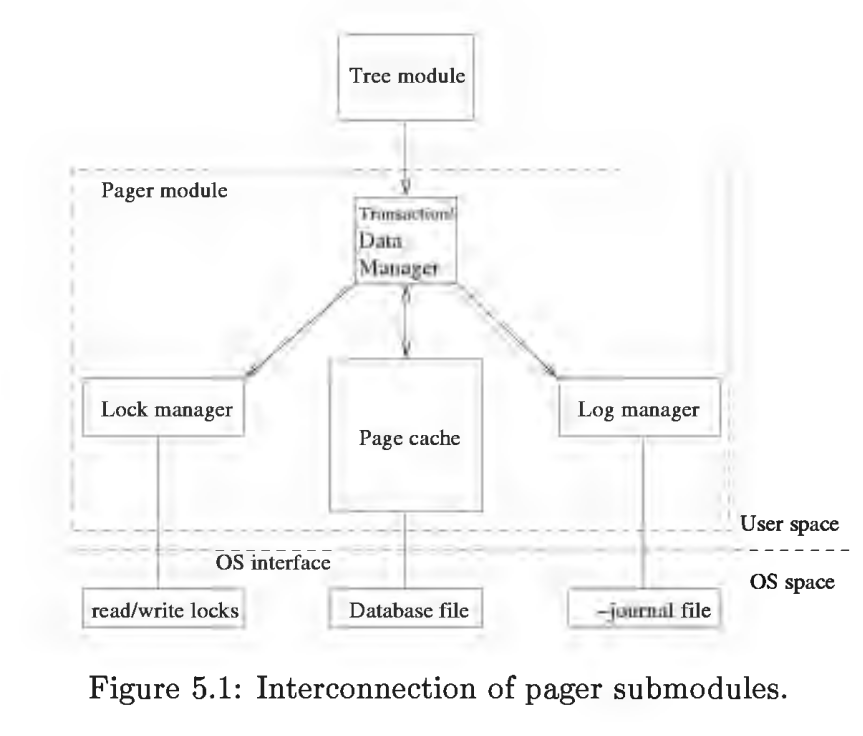
Page 接口
模块提供了 Pager 对象,它跟 database file 一一对应。tree moudle 使用 pager 来调用读写功能。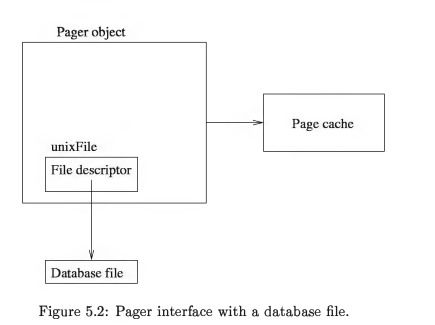
Pager 的结构中存储,日志文件描述符,数据库文件描述符,日志名,数据库文件名,页缓存,savepoint 数组等信息。
当在用户事务中执行更新操作时是需要 savepoint 的用以失败时的回滚
所有接口函数的定义都在pager.c,函数名都是以 sqlite3Pager 开头
Page Cache
Page caches 位于应用进程的空间中,与操作系统的 cache 无关。每个进程中都保持独立的 Page Object,多个进程打开同一个 database file 的同一个区域,保存多份 page object。一个进程中的多个线程,他们既可以分别独立使用 cache 也可以共享 cache。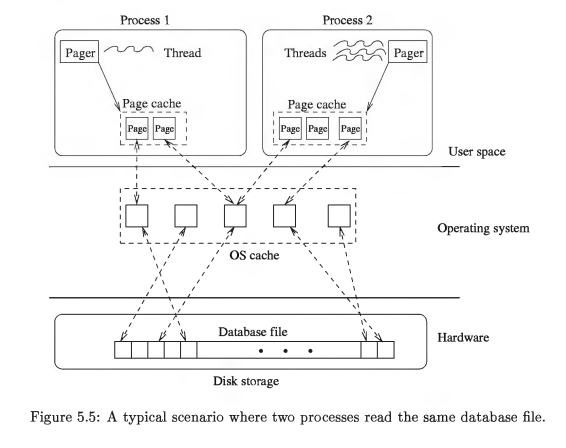
- Cache State
Pager 结构体中 eState 和 eLock 两个控制 pager 的行为。
eState 有 7 个状态:PAGE_OPEN(pager 刚刚创建),PAGER_READER(位于读事务中,pager 可以读), PAGER_WRITER_LOCKED(位于写事务中,pager 可以写),PAGER_WRITER_CACHEMOD(位于写事务中且 cache 已被修改),PAGER_WRITER_DBMOD(位于写事务中且开始向 db file 中写),PAGER_WRITER_FINISHED(位于写事务中且已写完 db file,准备提交),PAGER_ERROR(发生读写错误,则进入到 ERROR)。
eLock 可以使 Pager 位于如下 4 种状态中:NO_LOCK(pager 没有访问数据),SHARED_LOCK(在多个读事务中,对应的多个 pager 正在读),RESERVED_LOCK(pager 已经预定了 database file 但是还没有开始写),EXCLUSIVE_LOCK(在写事务中,pager 已经在写) 中。- 一次 pager 的状态转换过程:
- 一个 pager 刚开始是 NO_LOCK 状态;
- tree 模块调用 sqlite3PagerGet()获取 page,pager 进入到 SHARED_LOCK 状态中;
- tree 模块调用 sqlite3PagerUnref()释放所有 page,pager 进入到 NO_LOCK 状态;
- tree 模块调用 sqlite3PagerWrite(),pager 进入到 RESERVED_LOCK 状态;
- pager 进入到 EXCLUSIVE_LOCK,在真正将 page 修改写入到 database file 前;
- 在 sqlite3PagerRollback 或 sqlite3PagerCommit 执行过程中,pager 进入到 NO_LOCK 状态。
- 一次 pager 的状态转换过程:
- Cache 组织
每个 page cache 都通过一个 PCache handler 对象管理,pager 拥有 PCache handler 对象引用。如下是 PCache 对象的一些成员变量。
为了理解Page的重点内容,这里解释下方的图Pager 对象作为整个 Page 模块的主要对象,Pager 定义了成员PCache *pPCache。PCache 定义了成员sqlite3_pcache *pCache,这里 sqlite3_pcache 是一个可插拔模块,PCache1 实现了这个模块。PCache1 结构体中定义了PgHdr1 *apHashPgHdr1 是对 PgHdr 的具体实现。虚线框带包 page cache 的部分,这部分是可插拔的,接口在 sqlite3_pcache_methods2 中定义,PCache1 实现了这些接口。在 hash 桶的 slot 中分为 PgHdr1 和 slot image 两部分。slot image 持有:PgHdr, a database page image, 一个 private data 用于 btree 保存 page 相关的控制信息。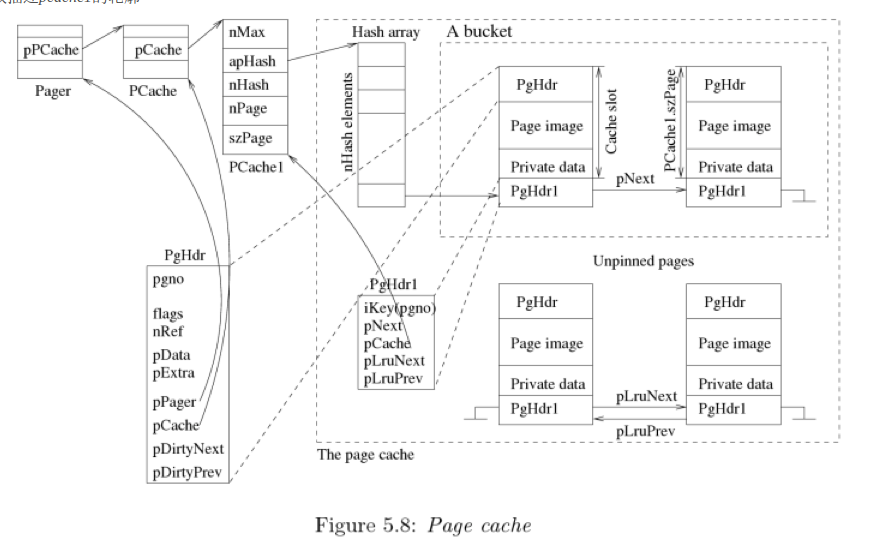
- Cache 读
对 cache 进行读,使用 page number 作为 key 在 hash 表中搜索,如果搜到则返回。如果没有搜到从 disk 中加载到 cache,然后返回。如果加载时 hash table 没有空间了,则需要删除不用的 page 来加载新的 page,或者将脏页刷进 disk 来回收 page。
返回 page 后,改 page 标记为 pinned,使用后 unpinned。这个标记用于回收 page 时使用。 - Cache 写
写时需要先刷 journal log,然后再写。同时写的过程中为 dirty,等待内容被刷入 disk。 - Cache Fetch
SQlite 遵循 on command fetch,有些数据库能做到 prefetch。 - Cache 管理
基本原则:关键:cache 的管理是否合理的标准就是 cache 的命中率高不高。1
2
3(1) Whenever there is a page in the cache, there is also a master copy of the page in the database file. Whenever the cache copy is updated, the master copy may need to be updated too.
(2) For a requested page that is not in the cache the master copy is referenced and a new cache copy is made from the master.
(3) If the cache is full and a new page is to be placed in the cache, a replacement algorithm is invoked to remove some old page from the cache to make room for the new one. - Cache 回收机制
SQLite 使用了类似于 LRU 的机制。 - 源码阅读
testpcache 实现了 sqlite3_pcache_methods2 的接口可以认为是 sqlite3_pcache 的具体实现。可以通过阅读此部分源码,来理解 page cache 管理机制。https://blog.csdn.net/pfysw/article/details/79186613,最重要的函数 testpcacheFetch()。pgno 就是作为 hash 表中的 key。
事务管理
pager 通过管理锁和日志来达到管理事务的目的。它负责决定锁类型,锁获取释放的时机。负责决定日志的内容。它通过两阶段协议来管理并发事务的顺序执行。事务管理分为两个方面:正常流程和恢复流程。
正常流程
包括:读写 page,提交事务和 Statement 子事务,创建和保存 savepoints,回收 page cache 和刷新 page-cache 到 risk。- 读操作
sqlite3PagerGet()获取或创建 page 在 cache 中。在这个函数中,先获取 shared lock。读取成功后返回指向这个 page cache 的指针。如果是第一次读,这里可以参考 5.8figure,它将 private data 初始化为 0,然后供 tree moudle 调用初始化并存储数据。如何第一次获取锁,在获取 shared lock 时,会判断 hot journal file,如果存在则会先回滚。
最后,在 hashtable 中为 page 找到一个位置,然后将 disk 内容载入。 - 写操作
sqlite3PagerWrite(),负责 pinned the page。pager 需要获得 reserved lock,然后再升级为 exclusive lock。同时要在日志中写入旧数据并刷入 risk。再写入数据到 cache,最后刷到 risk。如果磁盘扇区大于 page 尺寸,则 SQLite 记录整个扇区而不是 page 到日志中。如果已经将 page 信息 copy 到 journal 文件中,则这个 page 不会有新的记录在 journal 文件中,因为这个 journal file 只负责回滚到事务最初状态。 - Cache 刷盘
在两种情况下刷盘:1.cache 满了;2.事务提交。刷盘时先刷日志再刷数据。
具体过程参考:https://www.sqlite.org/atomiccommit.html - Commit 操作
tree moudle 先调用 sqlite3PagerCommitPhaseOne(),获取 exclusive 锁然后调用系统 IO 接口写入数据并通过 fsync 强制刷盘。后调用 sqlite3PagerCommitPhaseTwo(),关闭 journal file,释放锁并降级锁至 NO_LOCK。
commit 的时间点发生在 journal file 被删除,这样才能保证宕机后不会让旧值覆盖了新值。
Multidatabase 的情况,需要 VM moudle 来协调,因为 pager 只负责单个数据。这时有个 master journal file 负责记录 single journal file 保证所有单数据的事务能够同步提交或在宕机后回滚。多个数据库的事务之间有可能因为要获取相同的锁,而造成死锁。SQLite 通过 retry 机制来解决。 - Statement 操作
Statement 子事务按照匿名 savepoint 来实现,并且在结束时释放。分为 Read,Write,Commit 三种。Write 的操作有些复杂参看 SQLite Database System:5.4.1.5。 - Savepoints
创建 Savepoints,当一个用户事务创建一个 savepoint 后,SQLite 就进入了 Savepoint 模式。这个模式下 SQLite 不再删除 statment journal 当 Statement 提交时。而是等到释放所有 Savepoint 才释放。
这里 page 存储的方式不同(没有 Savepoint 时,一个 trasaction 只在 journal 中存储一份 page)。当一个 page 被前一个 Statement 加入了 Statement journal,那么这个 page 可以被当前 Statement 加入同一个 Statement journal。这样同一个 stat journal 拥有一个 page 的多个 log。
释放 savepoints。当执行 release sp 命令时,PagerSavePoint 对象将被销毁。
- 读操作
恢复过程
SQLite 需要能够将数据库从错误中恢复,保证数据库的一致性。分为四种情况。- Transaction abort
当事务持有 RESERVED 或 PENDING lock 时,意味着数据文件没有被改变,所以 pager 删除缓存和 journal 文件即可。当事务持有 EXCLUSIVE lock 时,意味数据文件已经被改变。则需要扫描 journal 文件,恢复数据文件中原本的内容和大小,删除缓存,最后释放 EXCLUSIVE lock。 - Statement subtransaction abort
SQLite 回滚所有日志从 statement journal 和 rollback journal。 - Reverting to savepoints
SQLite 从 Statement journal file 中重放 Savepoint 之后的日志。其中 PagerSavepoint 对象的三个成员很关键:iOffset,iHdrOffset,iSubRec。如果是回滚整个事务,那么只需要回滚 rollback journal 并删除所有 PagerSavepoint 对象。 - Recovery from failure
当系统发生宕机后,如果系统中有残留的 journal file 则意味着写事务在执行时失败了,需要使用 journal file 来回滚。
整体流程如下:- 获取 SHARED LOCK 在 database file
- 检查是否存在 hot journal file,如果没有则不需要恢复,如果有则继续按照如下步骤执行。
- 获取 EXCLUSIVE LOCK 在 database file。如果获取失败,则意味着另一个 pager 正在执行恢复。这是他返回 SQLITE_BUSY
- 它读取所有日志记录从 rollback journal file 并且回滚。
- 回滚后刷新磁盘,让记录存入 disk file。
- 删除 journal file
- 删除 master journal file 如果需要的话
- 将 lock 等级从 EXCLUSIVE 降低到 SHARED
检测 master journal 过期。如果 mj 中所有 rollback journal 都已经不存在,那么就删除 mj。
- Transaction abort
其他管理问题
- 检查点
有时为减少故障恢复的时间,一些 database 会定期执行检查点,使得系统出错时可以直接从检查点恢复。SQLite 在 3.7.0 之前的版本并没有检查点。之后才引入检查点。 - 空间约束
一些 database 在回滚事务时产生了新的日志,此时可能会遇到问题,当系统没有更多空间来存储 journal file 时。SQLite 不会有这个问题,因为在回滚事务时,它不产生新的日志。但是空间不够在某种情况下,也会对 SQLite 造成影响。例如一种极端情况:事务执行时删除了一些数据导致 database file 缩小,当要恢复时文件系统的空间被操作系统其他进程占用了,导致无法在回滚时申请到所需要的空间。
- 检查点