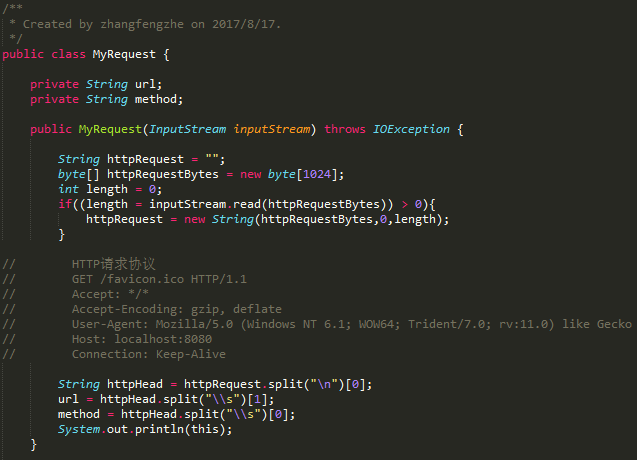
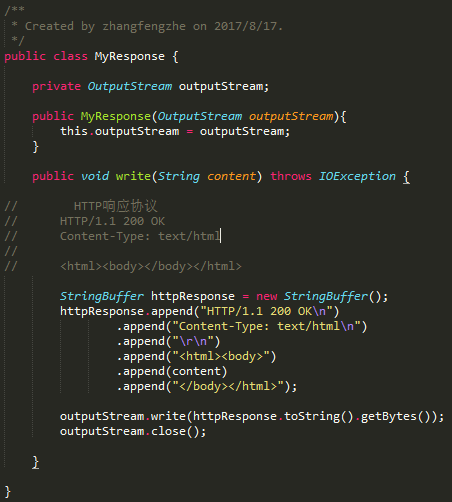
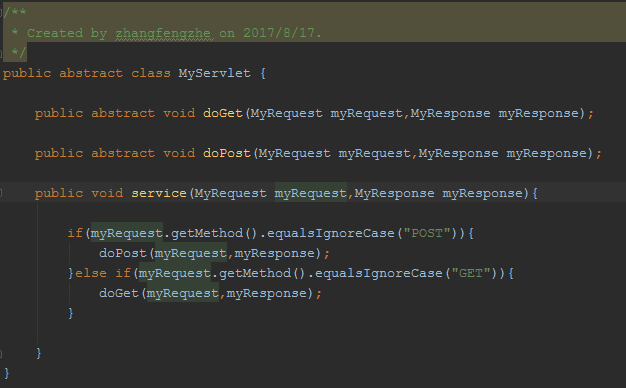
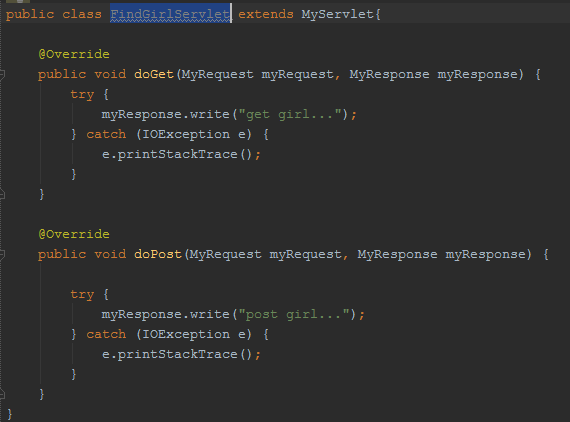
gRPC和Protobuf
gRPC 是什么?
参考 http://doc.oschina.net/grpc?t=58008
在 gRPC 里客户端应用可以像调用本地对象一样直接调用另一台不同的机器上服务端应用的方法,使得您能够更容易地创建分布式应用和服务。与许多 RPC 系统类似,gRPC 也是基于以下理念:定义一个服务,指定其能够被远程调用的方法(包含参数和返回类型)。在服务端实现这个接口,并运行一个 gRPC 服务器来处理客户端调用。在客户端拥有一个存根能够像服务端一样的方法。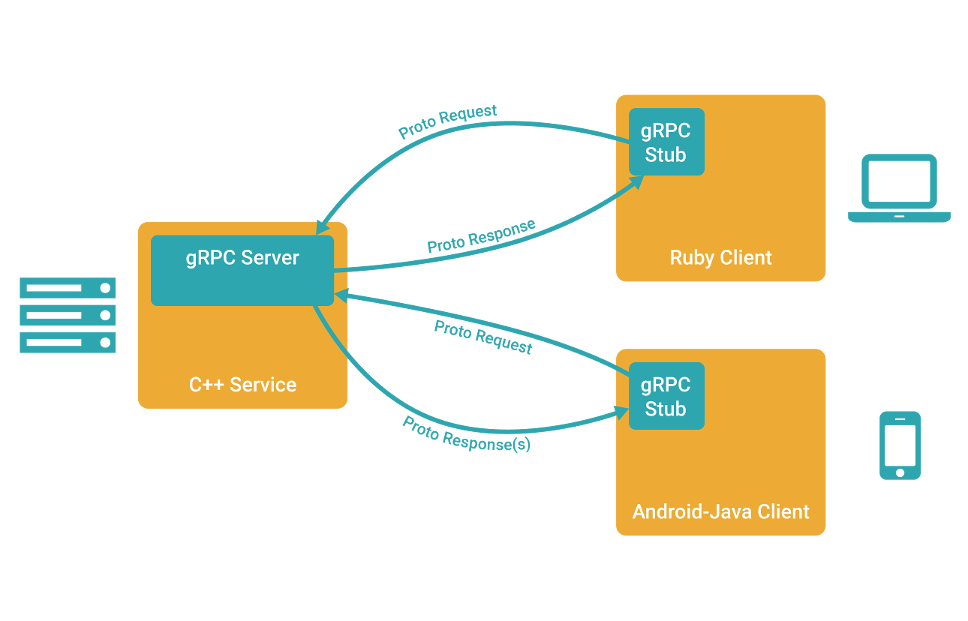
gRPC 客户端和服务端可以在多种环境中运行和交互 - 从 google 内部的服务器到你自己的笔记本,并且可以用任何 gRPC 支持的语言来编写。所以,你可以很容易地用 Java 创建一个 gRPC 服务端,用 Go、Python、Ruby 来创建客户端。
使用 protocol buffers
gRPC 默认使用 protocol buffers,这是 Google 开源的一套成熟的结构数据序列化机制(当然也可以使用其他数据格式如 JSON)。正如你将在下方例子里所看到的,你用 proto files 创建 gRPC 服务,用 protocol buffers 消息类型来定义方法参数和返回类型。
protobuf 定义服务,JAVA 实现
protobuf 的详细用法https://blog.51cto.com/9291927/2331980
1 | syntax = "proto3"; |
编译 protobuf 生成服务端接口和客户端存根
一旦定义好服务,我们可以使用 protocol buffer 编译器 protoc 来生成创建应用所需的特定客户端和服务端的代码 - 你可以生成任意 gRPC 支持的语言的代码,当然 PHP 和 Objective-C 仅支持创建客户端代码。生成的代码同时包括客户端的存根和服务端要实现的抽象接口,均包含 Greeter 所定义的方法。
以下类包含所有我们需要创建这个例子所有的代码:
- HelloRequest.java, HelloResponse.java 和其他文件包含所有 protocol buffer 用来填充、序列化和提取 HelloRequest 和 HelloReply 消息类型的代码。
- GreeterGrpc.java, 包含 (还有其他有用的代码):
Greeter 服务端需要实现的接口
1 | public static interface Greeter { |
客户端用来与 Greeter 服务端进行对话的 存根 类。就像你所看到的,异步存根也实现了 Greeter 接口。
1 | public static class GreeterStub extends AbstractStub<GreeterStub> |
写一个服务器
现在让我们写点代码!首先我们将创建一个服务应用来实现服务
服务实现
GreeterImpl.java 准确地实现了 Greeter 服务所需要的行为。
正如你所见,GreeterImpl 类通过实现 sayHello 方法,实现了从 IDL 生成的 GreeterGrpc.Greeter 接口 。
1 | public static GreeterImpl impliment Greeter { |
sayHello 有两个参数:
- HelloRequest,请求。
- StreamObserver
: 应答观察者,一个特殊的接口,服务器用应答来调用它。
为了返回给客户端应答并且完成调用:
- 用我们的激动人心的消息构建并填充一个在我们接口定义的 HelloReply 应答对象。
- 将 HelloReply 返回给客户端,然后表明我们已经完成了对 RPC 的处理。
服务端实现
需要提供一个 gRPC 服务的另一个主要功能是让这个服务实在在网络上可用。
HelloWorldServer.java 提供了以下代码作为 Java 的例子。
1 | /* The port on which the server should run */ |
客户端实现
客户端的 gRPC 非常简单。在这一步,我们将用生成的代码写一个简单的客户程序来访问我们在上一节里创建的 Greeter 服务器。
首先我们看一下我们如何连接 Greeter 服务器。我们需要创建一个 gRPC 频道,指定我们要连接的主机名和服务器端口。然后我们用这个频道创建存根实例。
1 | private final ManagedChannel channel; |
在这个例子里,我们创建了一个阻塞的存根。这意味着 RPC 调用要等待服务器应答,将会返回一个应答或抛出一个异常。 gRPC Java 还可以有其他种类的存根,可以向服务器发出非阻塞的调用,这种情况下应答是异步返回的。
- 我们创建并填充一个 HelloRequest 发送给服务。
- 我们用请求调用存根的 SayHello(),如果 RPC 成功,会得到一个填充的 HelloReply ,从其中我们可以获得 greeting。
gRPC 进阶
在 protobuf 中定义服务
1 | syntax = "proto3"; |
生成客户端和服务端代码
接下来我们需要从 .proto 的服务定义中生成 gRPC 客户端和服务器端的接口。我们通过 protocol buffer 的编译器 protoc 以及一个特殊的 gRPC Java 插件来完成。为了生成 gRPC 服务,你必须使用 proto3 编译器。
下面的类都是从我们的服务定义中生成:
- 包含了所有填充,序列化以及获取请求和应答的消息类型的 Feature.java,Point.java, Rectangle.java 以及其它类文件。
- RouteGuideGrpc.java 文件包含(以及其它一些有用的代码):
- RouteGuide 服务器要实现的一个接口 RouteGuideGrpc.RouteGuide,其中所有的方法都定 义在 RouteGuide 服务中。
- 客户端可以用来和 RouteGuide 服务器交互的 存根 类。 异步的存根也实现了 RouteGuide 接口。
创建服务器
让 RouteGuide 服务工作有两个部分:
- 实现我们服务定义的生成的服务接口:做我们的服务的实际的“工作”。
- 运行一个 gRPC 服务器,监听来自客户端的请求并返回服务的响应。
实现 RouteGuide
1 | public class RouteGuideServer { |
启动服务器
1 | public void start() { |
为了做到这个,我们需要:
- 创建我们服务实现类 RouteGuideService 的一个实例并且将其传给生成的 RouteGuideGrpc 类的静态方法 bindService() 去获得服务定义。
- 使用生成器的 forPort() 方法指定地址以及期望客户端请求监听的端口。
- 通过传入将 bindService() 返回的服务定义,用生成器注册我们的服务实现到生成器的 addService() 方法。
- 调用生成器上的 build() 和 start() 方法为我们的服务创建和启动一个 RPC 服务器。
创建客户端
创建存根
为了调用服务方法,我们需要首先创建一个 存根,或者两个存根:
- 一个 阻塞/同步 存根:这意味着 RPC 调用等待服务器响应,并且要么返回应答,要么造成异常。
- 一个 非阻塞/异步 存根可以向服务器发起非阻塞调用,应答会异步返回。你可以使用异步存根去发起特定类型的流式调用。
我们首先为存根创建一个 gRPC channel,指明服务器地址和我们想连接的端口号:
1 | channel = NettyChannelBuilder.forAddress(host, port) |
如你所见,我们用一个 NettyServerBuilder 构建和启动服务器。这个服务器的生成器基于 Netty 传输框架。
我们使用 Netty 传输框架,所以我们用一个 NettyServerBuilder 启动服务器。
现在我们可以通过从 .proto 中生成的 RouteGuideGrpc 类的 newStub 和 newBlockingStub 方法,使用频道去创建我们的存根。
1 | blockingStub = RouteGuideGrpc.newBlockingStub(channel); |
调用服务方法
简单 RPC
在阻塞存根上调用简单 RPC GetFeature 几乎是和调用一个本地方法一样直观。
1 | Point request = Point.newBuilder().setLatitude(lat).setLongitude(lon).build(); |
我们创建和填充了一个请求 protocol buffer 对象(在这个场景下是 Point),在我们的阻塞存根上将其传给 getFeature() 方法,拿回一个 Feature。
服务器端流式 RPC
接下来,让我们看一个对于 ListFeatures 的服务器端流式调用,这个调用会返回一个地理性的 Feature 流:
1 | Rectangle request = |
如你所见,这和我们刚看过的简单 RPC 很相似,除了方法返回客户端用来读取所有返回的 Feature 的 一个 Iterator,而不是单个的 Feature。
客户端流式 RPC
现在看看稍微复杂点的东西:我们在客户端流方法 RecordRoute 中发送了一个 Point 流给服务器并且拿到一个 RouteSummary。为了这个方法,我们需要使用异步存根。如果你已经阅读了
创建服务器,一些部分看起来很相近——异步流式 RPC 是在两端通过相似的方式实现的。
1 | public void recordRoute(List<Feature> features, int numPoints) throws Exception { |
如你所见,为了调用这个方法我们需要创建一个 StreamObserver,它为了服务器用它的 RouteSummary 应答实现了一个特殊的接口。在 StreamObserver 中,我们:
覆写了 onNext() 方法,在服务器把 RouteSummary 写入到消息流时,打印出返回的信息。
覆写了 onCompleted() 方法(在 服务器 完成自己的调用时调用)去设置 SettableFuture,这样我们可以检查服务器是不是完成写入。
之后,我们将 StreamObserver 传给异步存根的 recordRoute() 方法,拿到我们自己的 StreamObserver 请求观察者将 Point 发给服务器。一旦完成点的写入,我们使用请求观察者的 onCompleted() 方法告诉 gRPC 我们已经完成了客户端的写入。一旦完成,我们就检查 SettableFuture 验证服务器是否已经完成写入。
双向流式 RPC
最后,让我们看看双向流式 RPC RouteChat()。
1 | public void routeChat() throws Exception { |
和我们的客户端流的例子一样,我们拿到和返回一个 StreamObserver 应答观察者,除了这次我们在客户端仍然写入消息到 它们的 消息流时通过我们方法的应答观察者返回值。这里读写的语法和客户端流以及服务器流方法一样。虽然每一端都会按照它们写入的顺序拿到另一端的消息,客户端和服务器都可以任意顺序读写——流的操作是互不依赖的。
ProtoBuf 存储原理
核心是 Google 提出了“Base 128 Varints”编码,这是一种变字节长度的编码,官方描述为:varints 是用一个或多个字节序列化整形的一种方法。
序列化方式
protobuf 把 message 通过一系列 key_value 对来表示。
Key 的算法为:(field_number << 3)| wired_type
这里 field_number 就是具体的索引,wired_type 的值按下表查询。
| wired_type | .proto 类型 |
|---|---|
| 0 | Varint int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit fixed64, sfixed64, double |
| 2 | Length-delimited string, bytes, embedded messages, packed repeated fields |
| 5 | 32-bit fixed32, sfixed32, float |
| 对于 int,bool,enum 类型,value 就是 Varint。 |
而对于 string,bytes,message 等等类型,value 是长度+原始内容编码。
举例 int 类型存储(Varint 存储原理)
存储一个 int32 类型的数字,通常是 4 个字节。但是 Varints 最少只需要一个字节就可以了。
Varints 规定小于 128 的数字都可以用一个字节来表示,比如 10, 它就会用一个字节 0000 1010 来存储。
对于大于 128 的数字,则用更多个字节存储。
以 150 举例:protobuf 的存储字节是 1001 0110 0000 0001。
为什么会这样标识呢?首先我们了解一个字节共 8 位,表示的数字是 255,但是 Varints 只用一个字节表示小于 128 的数字,换句话说,就是 Varints 只用了 8 位中的 7 位来表示数字,而还有一位被用来干嘛了呢?
Varints 在官方规定中表示,每个字节的最高位是有特殊含义,当最高位为 1 的时候,代表后续的字节也是该数字的一部分。当最高位为 0 的时候,则表示结束。
比如过 150,二进制表示为 1001 0110。
先取后七位 001 0110, 作为第一个字节的内容。
再取余下 1 位,前面补 0 凑齐 7 位,就是 000 0001,作为第二字节。
对于 intel 机器,是小端字节序,低字节位于地址低的。0010110 是低字节地址,因此排在前面,因为后面的也是数字的一部分,所以高位补 1,也就成了 10010110。 同样的,高字节 000 0001,排在后面,并且它后面没有后续字节了,所以补 0,也就成了 0000 0001。
因此 150 在 protobuf 中的表示方式为 1001 0110 0000 0001。举例 string 类型存储
1
2
3message Test {
required string desc = 2;
}假如把 a 设置为 “testing”的话, 那么序列化后的就是
12 07 74 65 73 74 69 64 67
其中 12 是 key。剩下的是 value。
怎么算的呢?先看 12, 这里的 12,是个 16 进制数字,其二进制位表示为 0001 0010。
0010 就是类型 string 的对应的 Type 值,根据上表,也就是 2。
field_number (required string desc)是 2,也就是 0010,左移三位,就成了 0001 0000。
按照 key 的计算公式,和 Type 值取并后就变成了 0001 0010,即 12。
Value 是长度加原始内容编码。
07 就是长度, 代表 string 总长 7 个字节。 后面 7 个数字一次代表每个字母所对应的 16 进制表示。
json 与 protobuf 的互转
1 | <!-- https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java-util --> |
自定义的 bean 与 proto 是可以通过 Json 相互转换的,然而它们之间的转换需要第三方 JSON 转换工具和 protobuf util 的支持。
1 | //to Json |