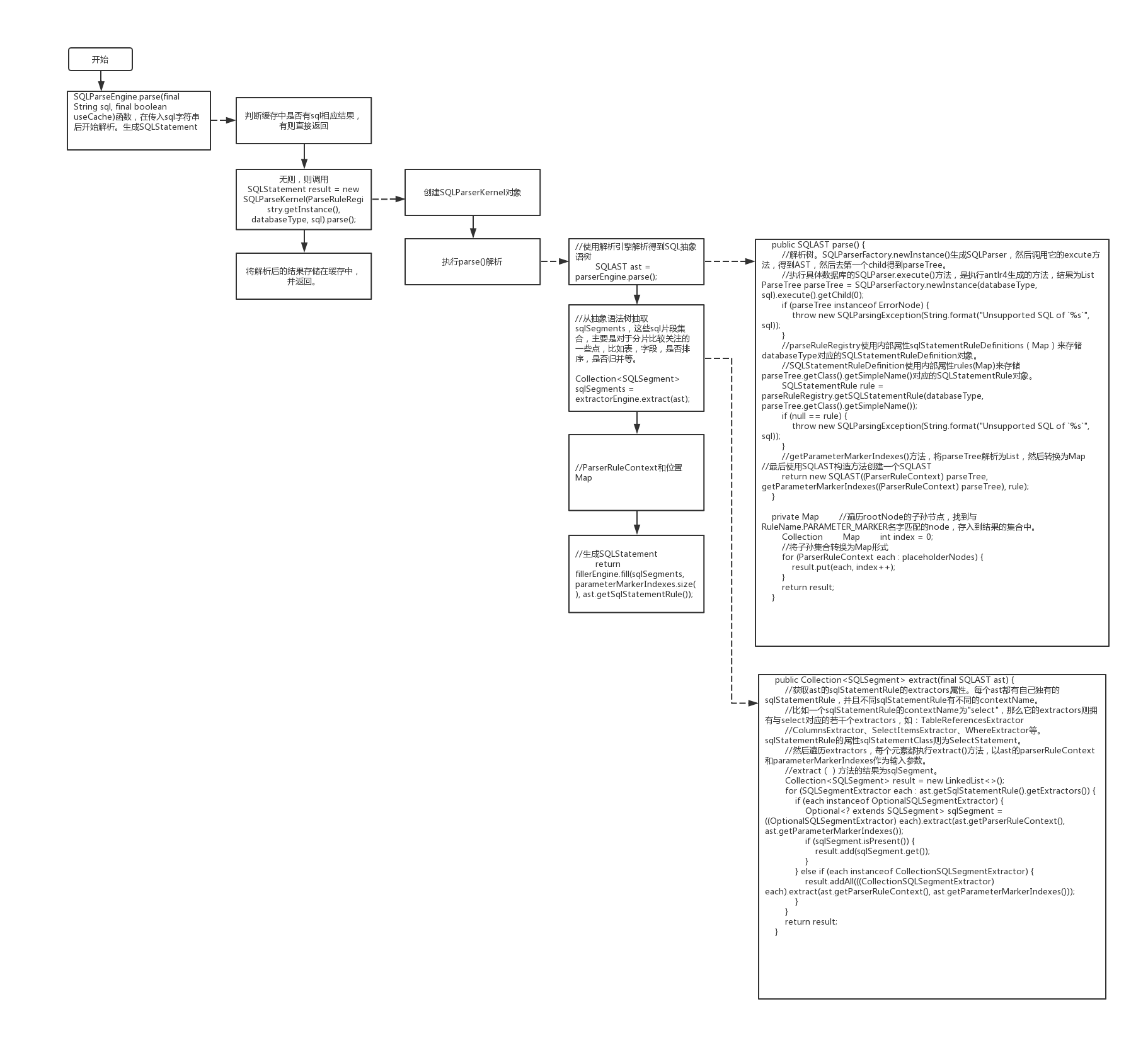
一、进程
传统上,Unix操作系统下运行的应用程序、 服务器以及其他程序都被称为进程,而Linux也继承了来自unix进程的概念。必须要理解下,程序是指的存储在存储设备上(如磁盘)包含了可执行机器指 令(二进制代码)和数据的静态实体;而进程可以认为是已经被OS从磁盘加载到内存上的、动态的、可运行的指令与数据的集合,是在运行的动态实体。这里指的 指令和数据的集合可以理解为Linux上ELF文件格式中的.text .data数据段。
二、进程组
每个进程除了有一个进程ID之外,还属于一个进程组,那什么是进程组呢?
顾名思义,进程组就是一个或多个进程的集合。这些进程并不是孤立的,他们彼此之间或者存在父子、兄弟关系,或者在功能上有相近的联系。每个进程都有父进程,而所有的进程以init进程为根,形成一个树状结构。
那为啥Linux里要有进程组呢?其实,提供进程组就是为了方便对进程进行管理。假设要完成一个任务,需要同时并发100个进程。当用户处于某种原因要终止 这个任务时,要是没有进程组,就需要手动的一个个去杀死这100个进程,并且必须要严格按照进程间父子兄弟关系顺序,否则会扰乱进程树。有了进程组,就可以将这100个进程设置为一个进程组,它们共有1个组号(pgrp),并且有选取一个进程作为组长(通常是“辈分”最高的那个,通常该进程的ID也就作为进程组的ID)。现在就可以通过杀死整个进程组,来关闭这100个进程,并且是严格有序的。组长进程可以创建一个进程组,创建该组中的进程,然后终止。只要在某个进程组中一个进程存在,则该进程组就存在,这与其组长进程是否终止无关。
进程必定属于一个进程组,也只能属于一个进程组。 一个进程组中可以包含多个进程。 进程组的生命周期从被创建开始,到其内所有进程终止或离开该组。
内核中,sys_getpgrp()系统调用用来获取当前进程所在进程组号;sys_setpgid(int pid, int pgid)调用用来设置置顶进程pid的进程组号为pgid。
三、作业
Shell分前后台来控制的不是进程而是作业(Job)或者进程组(Process Group)。一个前台作业可以由多个进程组成,一个后台也可以由多个进程组成,Shell可以运行一个前台作业和任意多个后台作业,这称为作业控制。
作业与进程组的区别:如果作业中的某个进程又创建了子进程,则子进程不属于作业。一旦作业运行结束,Shell就把自己提到前台,如果原来的前台进程还存在(如果这个子进程还没终止),它自动变为后台进程组。
四、会话
再看下会话。由于Linux是多用户多任务的分时系统,所以必须要支持多个用户同时使用一个操作系统。当一个用户登录一次系统就形成一次会话 。一个会话可包含多个进程组,但只能有一个前台进程组。每个会话都有一个会话首领(leader),即创建会话的进程。 sys_setsid()调用能创建一个会话。必须注意的是,只有当前进程不是进程组的组长时,才能创建一个新的会话。调用setsid 之后,该进程成为新会话的leader。
一个会话可以有一个控制终端。这通常是登陆到其上的终端设备(在终端登陆情况下)或伪终端设备(在网络登陆情况下)。建立与控制终端连接的会话首进程被称为控制进程。一个会话中的几个进程组可被分为一个前台进程组以及一个或多个后台进程组。所以一个会话中,应该包括控制进程(会话首进程),一个前台进程组和任意后台进程组。
一次登录形成一个会话
一个会话可包含多个进程组,但只能有一个前台进程组
五、控制终端
会话的领头进程打开一个终端之后, 该终端就成为该会话的控制终端 (SVR4/Linux)
与控制终端建立连接的会话领头进程称为控制进程 (session leader)
一个会话只能有一个控制终端
产生在控制终端上的输入和信号将发送给会话的前台进程组中的所有进程
终端上的连接断开时 (比如网络断开或 Modem 断开), 挂起信号将发送到控制进程(session leader)
进程属于一个进程组,进程组属于一个会话,会话可能有也可能没有控制终端。一般而言,当用户在某个终端上登录时,一个新的会话就开始了。进程组由组中的领头进程标识,领头进程的进程标识符就是进程组的组标识符。类似地,每个会话也对应有一个领头进程。
同一会话中的进程通过该会话的领头进程和一个终端相连,该终端作为这个会话的控制终端。一个会话只能有一个控制终端,而一个控制终端只能控制一个会话。用户通过控制终端,可以向该控制终端所控制的会话中的进程发送键盘信号。
同一会话中只能有一个前台进程组,属于前台进程组的进程可从控制终端获得输入,而其他进程均是后台进程,可能分属于不同的后台进程组。
当我们打开多个终端窗口时,实际上就创建了多个终端会话。每个会话都会有自己的前台工作和后台工作。