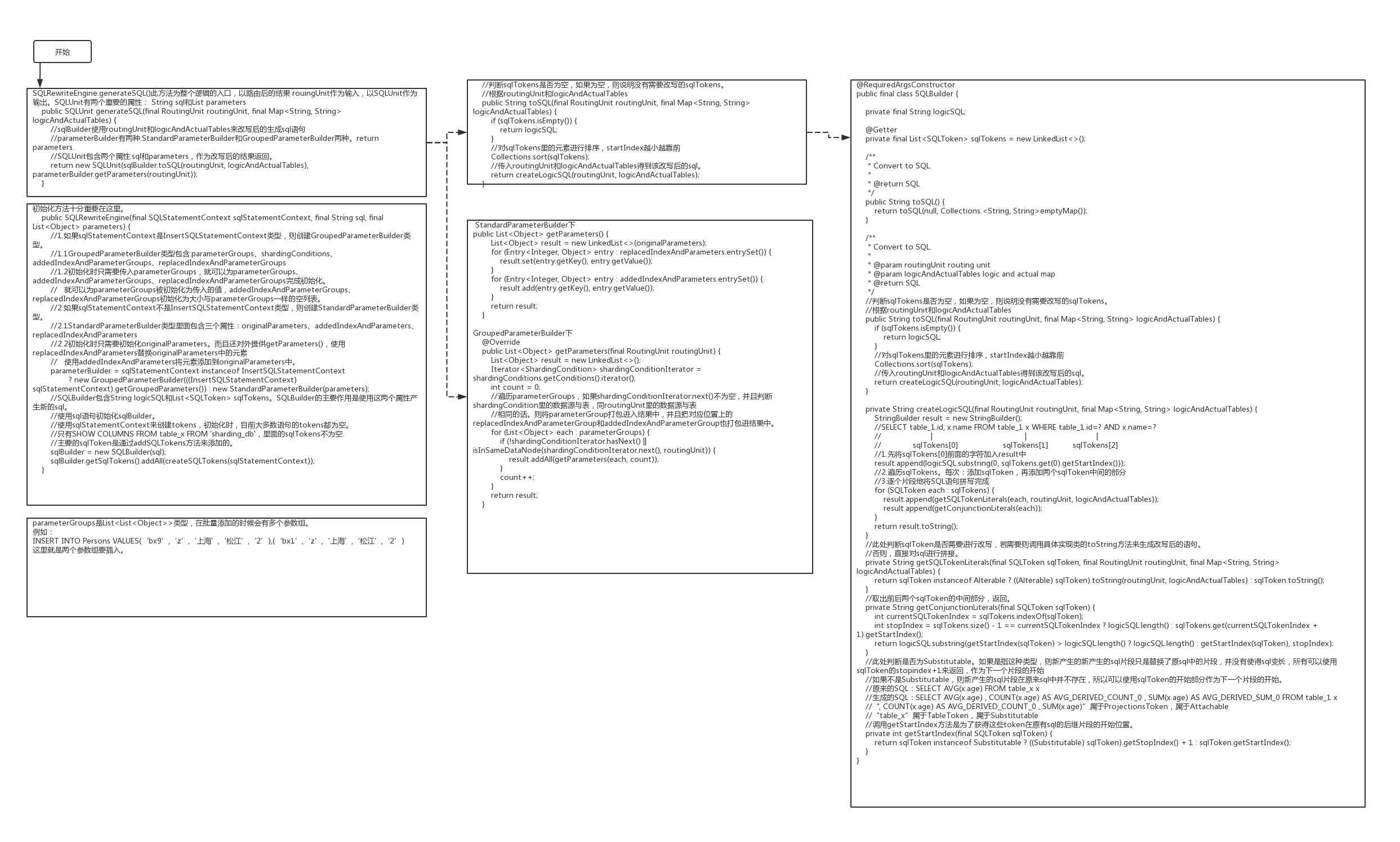
tmux相关
tmux 是 Linux 中窗口管理程序,适用于终端复用,尤其适合远程连接。最近,我正苦闷与 ssh 自动超时退出和 broken pipe,决定投入 tmux 怀抱。
使用 tmux 最直接的好处,便是可以在一个远程连接中开启多个控制台,而不用浪费额外的终端来连接远程主机。更不用说 tmux 方便的 attach/detach,随时保存工作状态,还有方便的复制粘贴功能。
基本使用
tmux 的主要元素分为三层:
Session: 一组窗口的集合,通常用来概括同一个任务。session 可以有自己的名字便于任务之间的切换。
Window: 单个可见窗口。Windows 有自己的编号,也可以认为和 ITerm2 中的 Tab 类似。
Pane: 窗格,被划分成小块的窗口,类似于 Vim 中 C-w +v 后的效果。
在安装好 tmux 后,直接在终端中输入 tmux 并回车,就进入了一个全新的 tmux 会话,输入 exit 即可退出。
可以在一台计算机上创建多个会话,并且通过为每个会话指定一个唯一的名称来管理它们:
tmux new-session -s basic
此命令可简化为:tmux new -s basic。
由于我们的程序是在 tmux 环境里运行的,因此需要一种方式来告诉 tmux 当前所输入的命令是为了让 tmux 去执行而不是 tmux 里的应用程序去执行,这就是命令前缀的作用。tmux 中默认的命令前缀是 CTRL-b 组合键,但 CTRL-b 组合键使用不是很方便,可将其修改为 CTRL-a 组合键。按下命令前缀组合键,松开,再按相应键,即发送 tmux 命令。
tmux 创建会话
- tmux new-session 创建一个未命名的会话。可以简写为 tmux new 或者就一个简单的 tmux
- tmux new -s development 创建一个名为 development 的会话
- tmux new -s development -n editor 创建一个名为 development 的会话并把该会话的第一个窗口命名为 editor
- tmux attach -t development 连接到一个名为 development 的会话
tmux 会话、窗口和面板的默认快捷键
- PREFIX d 从一个会话中分离,让该会话在后台运行。
- PREFIX : 进入命令模式
- PREFIX c 在当前 tmux 会话创建一个新的窗口,是 new-window 命令的简写
- PREFIX 0…9 根据窗口的编号选择窗口
- PREFIX w 显示当前会话中所有窗口的可选择列表
- PREFIX , 显示一个提示符来重命名一个窗口
- PREFIX & 杀死当前窗口,带有确认提示
- PREFIX % 把当前窗口垂直地一分为二,分割后的两个面板各占 50% 大小
- PREFIX “ 把当前窗口水平地一分为二,分割后的两个面板各占 50% 大小
- PREFIX o 在已打开的面板之间循环移动当前焦点
- PREFIX q 短暂地显示每个面板的编号
- PREFIX x 关闭当前面板,带有确认提示
- PREFIX SPACE 循环地使用 tmux 的几个默认面板布局
tmux 复制粘贴
- PREFIX [ 进入复制模式
- PREFIX ] 粘贴
进入复制模式后,可以用 vi 风格的快捷键进行移动(按上文的设置)。按下 sapce 就可以选择文本。回车键进行复制。然后再通过]进行粘贴。
也可以将复制粘贴设置为类似 vi 的模式,使用 esc 进入复制模式,v 进入粘贴模式,选择后 y 进行复制。Prefix-p 进行粘贴。
Copy and paste like in vim
unbind [
bind Escape copy-mode
unbind p
bind p paste-buffer
bind -t vi-copy ‘v’ begin-selection
bind -t vi-copy ‘y’ copy-selection
所有的复制都会被记录到缓冲区,输入#或者 tmux list-buffers 查看缓冲区,同时也进入了复制模式。也可以使用”=”来选择并粘贴缓冲区内容。tmux 的缓冲区和系统剪贴板是完全独立的。
自主配置
把前缀键从 C-b 更改为 C-a
set -g prefix C-a
释放之前的 Ctrl-b 前缀快捷键
unbind C-b
设定前缀键和命令键之间的延时
set -sg escape-time 1
确保可以向其它程序发送 Ctrl-A
bind C-a send-prefix
把窗口的初始索引值从 0 改为 1
set -g base-index 1
把面板的初始索引值从 0 改为 1
setw -g pane-base-index 1
使用 Prefix r 重新加载配置文件
bind r source-file ~/.tmux.conf ; display “Reloaded!”
分割面板
bind | split-window -h
bind - split-window -v
在面板之间移动
bind h select-pane -L
bind j select-pane -D
bind k select-pane -U
bind l select-pane -R
快速选择面板
bind -r C-h select-window -t :-
bind -r C-l select-window -t :+
调整面板大小
bind -r H resize-pane -L 5
bind -r J resize-pane -D 5
bind -r K resize-pane -U 5
bind -r L resize-pane -R 5
鼠标支持 - 如果你想使用的话把 off 改为 on
setw -g mode-mouse off
set -g mouse-select-pane off
set -g mouse-resize-pane off
set -g mouse-select-window off
设置默认的终端模式为 256 色模式
set -g default-terminal “screen-256color”
开启活动通知
setw -g monitor-activity on
set -g visual-activity on
设置状态栏的颜色
set -g status-fg white
set -g status-bg black
设置窗口列表的颜色
setw -g window-status-fg cyan
setw -g window-status-bg default
setw -g window-status-attr dim
设置活动窗口的颜色
setw -g window-status-current-fg white
setw -g window-status-current-bg red
setw -g window-status-current-attr bright
设置面板和活动面板的颜色
set -g pane-border-fg green
set -g pane-border-bg black
set -g pane-active-border-fg white
set -g pane-active-border-bg yellow
设置命令行或消息的颜色
set -g message-fg white
set -g message-bg black
set -g message-attr bright
设置状态栏左侧的内容和颜色
set -g status-left-length 40
set -g status-left “#[fg=green]Session: #S #[fg=yellow]#I #[fg=cyan]#P”
set -g status-utf8 on
设置状态栏右侧的内容和颜色
15% | 28 Nov 18:15
set -g status-right “#(~/battery Discharging) | #[fg=cyan]%d %b %R”
每 60 秒更新一次状态栏
set -g status-interval 60
设置窗口列表居中显示
set -g status-justify centre
开启 vi 按键
setw -g mode-keys vi
在相同目录下使用 tmux-panes 脚本开启面板
unbind v
unbind n
bind v send-keys “ ~/tmux-panes -h” C-m
bind n send-keys “ ~/tmux-panes -v” C-m
临时最大化面板或恢复面板大小
unbind Up
bind Up new-window -d -n tmp ; swap-pane -s tmp.1 ; select-window -t tmp
unbind Down
bind Down last-window ; swap-pane -s tmp.1 ; kill-window -t tmp
把日志输出到指定文件
bind P pipe-pane -o “cat >>~/#W.log” ; display “Toggled logging to ~/#W.log”